Video in het onderwijs heeft de afgelopen jaren een enorme vlucht genomen. In mijn eigen schooltijd diende de tv vooral als tijdvulling. Hij werd naar binnen gereden als er een docent ziek was geworden of op de laatste middag voor de vakantie. Zo herinner me de film The Wave bij Maatschappijleer, die we wel 2 of 3 keer hebben gezien.
In actuele onderwijsconcepten als MOOCs en Flipped Classroom is video een belangrijk medium. Het wordt gebruikt om colleges op te nemen (Weblectures), om stof uit te leggen (Kennisclips), vaardigheden te oefenen en observaties te doen. Ook moeten studenten steeds vaker een video als opdracht maken, in plaats van een schriftelijk verslag.
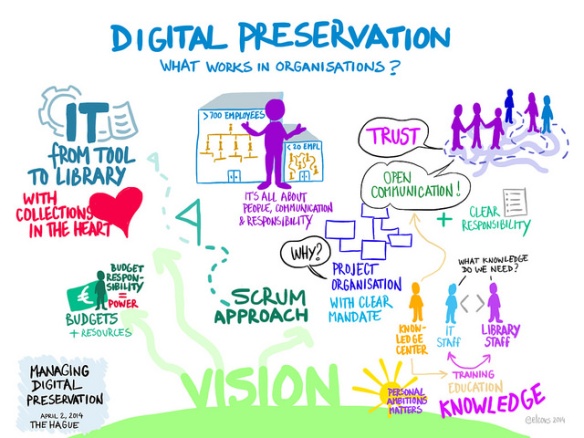
Van 8-10 maart bezocht ik in Brussel de Media & Learning Conference, om me eens goed te verdiepen in het gebruik van video in het hoger onderwijs. Nu de UBL immers het beheer over de universitaire videoserver heeft gekregen (Kaltura wordt momenteel geïmplementeerd), is het zaak dat we goed weten hoe medium wordt ingezet zodat we kunnen inspelen op wat er op ons af komt.

Bij video komt veel kijken. Weblectures zijn wel de meest elementaire vorm. Maar door het opnemen van colleges verandert een normaal efemere gebeurtenis ineens in een learning object, zoals Clive Young van University College London (bekijk op Slideshare) dat zo mooi zei. En dan komen er hele andere eisen om de hoek kijken. Kun je korte stukjes uit zo’n Weblecture bijvoorbeeld ook los gebruiken, of is een andere vorm dan geschikter? Voor iedere inzet van video die verder gaat dan eenvoudige college-opnamen moet worden nagedacht over wat je er precies mee wilt bereiken, en wat dan de meest geschikte vorm is. Een goede voorbereiding en een script – hoe beknopt ook – zijn daarbij onontbeerlijk.
Video is feitelijk een nogal passief medium, de student heeft de neiging om achterover te leunen. Maar zoals meerdere sprekers benadrukten: Learning does not happen until you stretch your brain. De student dient dus geactiveerd te worden. Toverwoorden daarbij zijn Engagement (betrokkenheid) en immersion (onderdompeling), volgens spreker Jeff Rubenstein, VP of Product van Kaltura (bekijk weblecture). Dit kan bijvoorbeeld door er vragen bij te stellen. Kaltura bevat functionaliteit om een video op bepaalde momenten te larderen met quizvragen – al verschillen de meningen over de inzet daarvan (het hindert bij het kijken of scannen door een video, en het zijn vaak oppervlakkige vragen). Ook kun je studenten actief met een video aan de slag laten gaan door hen uit meerdere scenario’s te laten kiezen (zoals bij deze film over wetenschappelijke integriteit), of hen te laten reflecteren op de inhoud. Met video kun je leermomenten in een verhalende vorm verpakken, waardoor studenten zich goed kunnen inleven en de stof beter beklijft.
![]() Kaltura doet jaarlijks onderzoek naar het gebruik van video in onderwijs. In The State of Video in Education 2015 (bekijk pdf) is onder andere gekeken naar digital literacy, inzet van video in cijfers, use cases, de behoeften van docenten, en een toekomst beeld van de inzet van video in het onderwijs. Docenten blijken vooral behoefte te hebben aan eenvoudige tools en workflows, een centrale videodienst die aan de leeromgeving is gekoppeld, maar zeker ook aan training, ondersteuning en tijd om hieraan te besteden.
Kaltura doet jaarlijks onderzoek naar het gebruik van video in onderwijs. In The State of Video in Education 2015 (bekijk pdf) is onder andere gekeken naar digital literacy, inzet van video in cijfers, use cases, de behoeften van docenten, en een toekomst beeld van de inzet van video in het onderwijs. Docenten blijken vooral behoefte te hebben aan eenvoudige tools en workflows, een centrale videodienst die aan de leeromgeving is gekoppeld, maar zeker ook aan training, ondersteuning en tijd om hieraan te besteden.
De didactische en praktische docentondersteuning blijft in Leiden bij de faculteiten, waar ook de Weblectures worden ondersteund en de afgelopen jaren studio-opstellingen zijn gerealiseerd dan wel gerevitaliseerd. Ook het Online Learning Lab van Centre for Innovation in Den Haag, waar de Leidse MOOCs worden geproduceerd, heeft studiofaciliteiten. De UBL zal bij dit alles een coördinerende rol bij spelen. De Media & Learning Conference heeft veel inspiratie gebracht hoe de ondersteuning van video bij andere universiteiten in binnen- en buitenland is georganiseerd.
Zo heeft de Vrije Universiteit Amsterdam (bekijk ppt) een walk-in studio ingericht, met vaste apparatuur en beperkte opties. Dit is geïnspireerd op Valencia en is een soort tussenvorm tussen Do It Yourself en een professionele studio. Er wordt gewerkt met een standaardprocedure. Je kunt boeken via een online formulier en de URL staat klaar als je de studio verlaat. Docenten zijn erg tevreden over deze dienst.
 De Universiteit Erlangen-Nürnberg (ppt) heeft een rugzak met opnameset. Dit aanbod is met name gericht op studenten. Er is een kleine training beschikbaar, maar deze is niet verplicht. Wel geven ze er een checklist bij met camera-instellingen en andere dingen waar je op moet letten (bv. omgevingsgeluid, camera niet richting raam plaatsen). Voor de voorbereiding hebben ze schema’s om structuur te bieden bij het bepalen van de didactische opzet en het maken van een script. De Oulu University of Applied Sciences (Finland) scoort hoge kijkcijfers met een video waarin het gebruik van de camera wordt gedemonstreerd.
De Universiteit Erlangen-Nürnberg (ppt) heeft een rugzak met opnameset. Dit aanbod is met name gericht op studenten. Er is een kleine training beschikbaar, maar deze is niet verplicht. Wel geven ze er een checklist bij met camera-instellingen en andere dingen waar je op moet letten (bv. omgevingsgeluid, camera niet richting raam plaatsen). Voor de voorbereiding hebben ze schema’s om structuur te bieden bij het bepalen van de didactische opzet en het maken van een script. De Oulu University of Applied Sciences (Finland) scoort hoge kijkcijfers met een video waarin het gebruik van de camera wordt gedemonstreerd.
Inholland (spreker Zac Woolfitt, bekijk ppt) heeft workshops van 2 uur opgezet, compleet met praktijkdeel (zelf optreden in video). De deelnemers leren zo meteen wat de valkuilen zijn. Er is veel tijd voor reflectie (nadenken hoe je dit goed kan doen en hoe je het goed kunt inzetten). In het natraject zijn er coaching sessies.
Bij diverse instellingen worden studenten actief betrokken bij het produceren van video. Zij zijn vaak creatiever en handiger met video dan docenten. Een video met het studentperspectief erin is bovendien aansprekend voor de doelgroep.
De productie van video wordt zo laagdrempelig mogelijk gehouden. Er wordt daarom veel met eenvoudige middelen gewerkt, en er vindt vaak geen controleslag voor publicatie plaats (mits de video alleen intern beschikbaar wordt gesteld). Hoogstens wordt er een label (gemaakt door studenten/docenten) aan gehangen. Voor de laagdrempeligheid is het ook belangrijk om de voorzieningen en ondersteuning zo dichtbij mogelijk te hebben. Docenten kunnen vaak geen dagdelen vrij plannen en moeten het tussendoor kunnen doen.
Aanpassen en updaten zijn lastig bij video. Hier kun je al rekening mee houden bij het maken van een nieuwe video. Gebruik bv. geen ‘talking head’, maar alleen audio boven een screencast of ander beeld. Let er bij de audio op dat je af en toe een pauze laat vallen, zodat achterhaalde informatie er later weer uitgeknipt en vervangen kan worden. Deze tips zijn van Jörn Loviscach (Fachhochschule Bielefeld, bekijk pdf), in Duitsland bekend om zijn kennisclips op het gebied van wiskunde. Nog een tip van hem: Maak opnames zoveel mogelijk met publiek. Desnoods vraag je een paar mensen als publiek te dienen. Hierdoor heb je een natuurlijkere presentatiestijl, waardoor de kijkers straks ook hun aandacht beter kunnen vasthouden. Voor de geluidskwaliteit wordt aanbevolen een usb-microfoon in plaats van de ingebouwde te gebruiken.
Als uitsmijter nog een tip:
Het Erasmus+ LoCoMoTion project van Jörn Loviscach, waarbij ook de TU Delft is betrokken, start op 17 mei met de meta-MOOC Making MOOCs on a Budget, met daarin ook veel tips over het maken van video. Allemaal meedoen: Video et vinco!
[youtube https://www.youtube.com/watch?v=6oDov1qTE_k&w=560&h=315]


 Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden:
Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden: https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg
https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg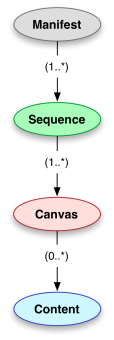 Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de
Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de