
Verschenen in IP 2019/2
Verschenen in IP 2019/2

Liber Pontificalis. UBL VLQ 60, fol. 20r. Images made with various filters of the White Light Portable Light Dome, developed by KU Leuven.
The materiality of historical artefacts and the development of new digital technologies might seem to contradict, however, quite the opposite is true. Increasingly digital technology is deployed to deepen our knowledge of cultural heritage in the broadest sense. On November 16. 2018 Leiden University Libraries invited a variety of speakers to discuss the rediscovery of historical artefacts through new technology, by focusing not only on the technology itself but also on the implications for historical research and our understanding of our material heritage.
The symposium is part of the program Beyond content, with which the UBL focuses on the materiality of text and images through a series of activities like workshops, presentations and an exhibition. Specific attention is paid to the forms in which historical texts and images have been handed down, but also to the digital techniques that have recently been developed to better study them. For more information on the programme see the website Beyond content.
The speakers introduced us to a range of methods, tools and algorithms often borrowed from the beta sciences and applied within the humanities. That these do not always need to be high end and expensive, was shown by the first keynote speaker Kate Rudy (University of St Andrews/NIAS). In her presentation Four technologies to spy on the past, she talked about the projects she will start as part of her upcoming Leverhulme Fellowship. As a medieval art historian she is interested in the production and use of illuminated manuscripts. In an earlier project she studied the use of texts and miniatures in a manuscript by measuring the grime with a densitometer. The calliper she will use to measure parchment thickness costs only 100 EUR, but serves perfectly find out whether leaves or quires were added to a manuscript.
Rudy also stressed the importance of handheld amateur photography. When libraries digitise a manuscript, they often focus on lavishly decorated and untouched manuscripts. But many researchers like her are particularly interested in the ugly, worn and broken ones. And cleaning a manuscript as part of a conservation project will lead to loss of information on the use of a manuscript as well. When researchers visit our library, they take many pictures from unstudied and non-digitised manuscripts or from surprising angles. These pictures are sometimes shared on Twitter, but most of the time they are only kept on standalone computers, unavailable to others. Although a lot of researchers do use free cloud storage like Google Photos and Flickr, this is not a reliable solution; the platforms can change the terms and conditions (Flickr recently limited the possibilities for free accounts), and sometimes simply shut down (just think of Picasa). This led to an interesting public discussion: do research institutions have a responsibility to store and share the results of DIY digitization? As a service it turned out to be very much desired by researchers.
Hannah Busch (Huygens ING) participated in the eCodicology project, in which several tools were developed to analyse large amounts of data taken from medieval manuscripts. In her presentation Machines and Manuscripts: New technologies for the exploration of medieval libraries she explained the use of algorithms for the automatic identification of lay-out elements, like columns, initials and miniatures. These data are added to the information taken from the descriptions in traditional catalogues. When combined they form a rich source for data visualisations of libraries as a whole. This makes it possible to gain better insight in book historical aspects like the relationship between format and size, or the percentage of manuscripts with decorations or miniatures.
In her new project at Huygens KNAW called Digital forensics for historical documents. Cracking cold cases with new technology the goal is to build a tool for script analysis in manuscripts based on convolutional neural networks. This technique is also used in image- and face technology.[1]
Meanwhile Hannah Busch offered a very useful summary of the needs of researchers as well. What she wants is to:
A prerequisite for this is of course to have the data FAIR: findable, accessible, interoperable and reusable.
Francien Bossema (Centrum Wiskunde en Informatica/Rijksmuseum/UvA) demonstrated the FlexRay Lab, a method for 3D visualisation using XRays and CT.[2] The non-invasive method can be used for medical imaging and food industry, but also for art historical research.

With the CT scanner it is possible to look inside objects in 3D during the scanning process. Together with the Rijksmuseum a workflow was developed that can be used both for both research during a conservation process and to reconstruct a production process. Bossema explained the method by reconstructing the production of a so-called Chinese puzzle ball. These decorative balls were made in the mid-18th ct from one single piece of ivory, consisting of several concentric spheres each of which rotates freely. Using the CT scanner it became clear that the spheres were made with a set of “L” shaped tools with progressively lengthening cutters. Only the outermost balls were carved elaborately.[3] Currently, they are working on an in-house scanner for the Rijksmuseum, to make the transition from 2D to 3D scanning possible by providing a standardised process for art historical research. As a result of these activities the Rijksmuseum is collecting large amounts of data. The museum is thus entering a new field and cooperation with institutions with more experience in this field, such as research institutes and libraries, is necessary.
The last years libraries and archives are increasingly confronted with growing collections of born digital scholarly archives. Peter Verhaar is working both for the Centre for Digital Scholarship of Leiden University Libraries and for the master’s programme in Book and Digital Media Studies. In his presentation Durable Access to Book Historical Data he discussed the challenges he was faced with in the acquisition of the digital archive of Professor Paul Hoftijzer. Hoftijzer, who is working on the Leiden book trade in the early modern period, has produced a rich collection of Word documents and Excel spreadsheets that he wanted to donate to the library. As a first step, Verhaar cleaned the unstructured data and transposed them to a database in systematic format. This essentially resulted in a new archive. The question for the audience was whether both of the archives should be kept. Cleaning up the “data grime” will in either case lead to a loss of information, in the same way as cleaning a physical manuscript does.
The pilot is also set up to raise awareness among researchers. The university library offers courses in data management to ensure that researchers know how to make their data FAIR. But we are now in the middle of a transition, researchers who are retiring the next couple of years never received these instructions, and in case no measures are taken, this will lead to loss of research data. Paul Hoftijzer, who was also attending the symposium, stressed the importance of keeping both a personal and a professional archive. In his opinion, only the combination of both can ensure a correct interpretation of the data.
Martijn Storms (Leiden University Libraries) introduced the audience to the crowdsourcing project Maps in the crowd that is running for more than 3 years now and has been very successful. With the help of enthusiastic volunteers almost 10.000 maps have been georeferenced, which means that users can find and use maps in an intuitive, geographic way, by browsing on a map. The maps can also be used in geographical data systems, e.g. to facilitate landscape analysis. The project attracted a lot of press, providing a large audience of map enthusiasts the opportunity to connect with the library and the collections.
In the afternoon the audience was invited to participate in an introductory workshop to IIIF.  You can try it out yourself here: https://digitalscholarship.nl/workshop/
You can try it out yourself here: https://digitalscholarship.nl/workshop/
Additionally, a pop-up exhibition was set up showing a selection of materials from the collection.
The final keynote by Giles Bergel (University of Oxford) focused on the physical and material aspects of the digital. He started his paper called Beyond fixity: the printing press in the age of digital reproduction by telling the story of the Doves press, responsible for the famous Doves font. After the two partners Thomas James Cobden-Sanderson and Emery Walker got into a severe dispute about the rights on the matrices in 1913, Cobden-Sanderson threw all of them into the Thames river. Since 2013 the Doves Type has been revived digitally by the designer Robert Green. He managed to recover 150 pieces of the original type from the Thames, which helped him to reproduce the font, including the imperfections of the original matrices. This story shows that “digital”, although increasingly experienced as something immaterial or even imaginary, has a materiality in itself as well. This sense of materiality is essential for book historical research, even when this is performed with a laptop and a package of software.
Giles Bergel is part of the Visual Geometry Group in Oxford, where tools are developed for visual analysis in of image and video content in a variety of academic disciplines like Humanities, History and Zoology. He is also Digital Humanities Ambassador in the Seebibyte project. One of the open source products developed is VISE, an application that can be used to make a large collection of images searchable by using image regions as query. VIA is an image annotation tool that can be used to define regions in an image and create textual descriptions of them. The Traherne digital collator finally makes it easy to compare copies of the same text in order to identify variants between them. Thanks to this tool, researchers no longer have to follow the so-called “Wimbledon-method” to compare prints, which means that headaches are fortunately something from the past.
The presentations can be found here:
[1] For an introduction see: https://adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/ or read this article by Dominique Stutzmann in which the same technology is applied: https://journal.digitalmedievalist.org/articles/10.16995/dm.61/
[2] For more information on the project: https://www.cwi.nl/research/groups/computational-imaging
[3] https://www.cwi.nl/events/cwi-scientific-meetings-1/cwiscientific.pdf With images and extensive description.

Een kort overzicht:
De Bibliothekartag is het grootste Duitse (en Duitstalige) congres voor bibliothecarissen. Het is ieder jaar een drukte van belang en met 4 dagen lang de hele dag door 20 (!) parallelsessies is het soms lastig te bepalen waar je aandacht naartoe moet. Ik bezocht de Bibliothekartag als I&P’er, maar nog meer als lid van het Innovatieteam.
Sommige thema’s werden net als in 2017 weer veel besproken. Denk bijvoorbeeld aan de ‘bibliotheek der dingen’, MakerSpaces (bijv. iLab, virtual reality, etc), en er ging zoals ieder jaar weer veel aandacht naar bibliotheekopleidingen. Meer focus dan vorig jaar lag er op Gamification binnen bibliotheken.
Een speciaal thema dit jaar was populisme en omgang met extreemrechts in de huidige bibliotheekwereld. Dit thema werd ondersteund door een aantal lezingen over de geschiedenis van nationaal-socialisme en roofkunst ten tijde van de Tweede Wereldoorlog specifiek met betrekking op bibliotheken. Ook was er tijdens de conferentie een tentoonstelling te vinden over “Berliner Bibliotheken im NS”.
De Open Repositories (OR) Conferentie wordt elk jaar in juni gehouden, telkens in een andere stad in de wereld. Als je op de hoogte wilt blijven van wat er zoal gebeurt in de wereld van de open source repository systemen, dan is dit wel the place to be. Er zijn vertegenwoordigers aanwezig van alle grote open source systemen, zoals DuraSpace (voor DSpace), Samvera (voor Hyrax – voorheen Hydra genoemd), Islandora, ePrints, Fedora, Dataverse en Invenio. Er wordt altijd voor een uitgebreid programma gezorgd, met niet alleen lezingen, maar ook workshops, presentaties in Pecha Kucha stijl, een ideas challenge en poster presentaties.
Hierdoor trekt de conferentie een gemêleerd publiek bestaande uit ontwikkelaars, project managers en data librarians afkomstig van alle continenten. Ook wordt er altijd voor een uitgebreid sociaal programma gezorgd, waardoor je met veel collega’s in contact komt. Ook dit jaar ben ik dan ook weer met veel inspiratie en een zee aan ideeën teruggekeerd.
 De locatie dit jaar was Bozeman, Montana in de VS, een staat die bekend is door Yellowstone Park, grizzly beren en vliegvissen. Bozeman zelf is een idyllisch groen universiteitsstadje met prachtige houten huizen, dat wordt omringd door sappige groene velden en wit-besneeuwde bergtoppen. Iedereen lijkt er bovendien een pickup, een pet en een hond te hebben. Terwijl op de deur van de UB duidelijk stond aangegeven dat dieren niet welkom waren, trof ik ze regelmatig aan op de campus:
De locatie dit jaar was Bozeman, Montana in de VS, een staat die bekend is door Yellowstone Park, grizzly beren en vliegvissen. Bozeman zelf is een idyllisch groen universiteitsstadje met prachtige houten huizen, dat wordt omringd door sappige groene velden en wit-besneeuwde bergtoppen. Iedereen lijkt er bovendien een pickup, een pet en een hond te hebben. Terwijl op de deur van de UB duidelijk stond aangegeven dat dieren niet welkom waren, trof ik ze regelmatig aan op de campus:
En hoewel de meeste Amerikaanse steden per voorkeur met de auto dienen te worden doorkruist, leent deze stad zich juist voor wandelen en fietsen. Op de campus van Montana State University trof ik zelfs deze fietsreparatie-paal aan.
De studenten bleken er zelf om te hebben gevraagd en de plaatsing zelfs mede-gefinancierd te hebben. Wat een geweldige service, je vraagt je af waarom wij dit niet al lang hebben!
Montana is niet naast de deur en mogelijk maakte dit dat er maar weinig Nederlanders of Nederlands-sprekenden aanwezig waren. Naast mij waren alleen twee UBA collega’s en twee medewerkers van Atmire aanwezig, service provider van DSpace en de hoofdsponsor van de conferentie. Thema was “Sustaining Open”. Zoals ze zelf verklaren op hun website: “Submissions this year should focus on the how, why, and what it will take to make open sustainable.”

De ‘binnenstad’ van Bozeman
De eerste dag van OR staat traditioneel in het teken van de workshops. Ik had me ingeschreven voor een sessie rondom Polaris OS, een nieuw systeem waar ik nog niet eerder van had gehoord. De Franse makers presenteren het als een Next Generation Open Repository, aansluitend bij de aanbevelingen van COAR (waar ik vorig jaar ook al wat over geschreven heb). Het is volgens hen data-georiënteerd, eenvoudig te installeren en interoperabel. Het valt al snel op dat er veel tijd en aandacht is besteed aan het meertalig maken van een repository (heel praktisch voor Franstaligen natuurlijk). Ook technisch ziet het er veelbelovend uit: er is een deposit module met embargo mogelijkheden en uitgebreid rechtenbeheer. Wel blijkt uit de uitgebreide demonstratie dat het systeem toch ingewikkelder in elkaar zit dan ik dacht. Het doet me denken aan Drupal, het CMS van Islandora waar zoveel opties in ‘verstopt’ zitten dat je door de bomen het bos niet meer ziet. Het is de vraag of je dit zomaar zonder uitgebreidere training kunt gaan gebruiken in je instelling. Bovendien staat Polaris nog in de kinderschoenen. Zo is het onduidelijk of er al wel echte gebruikers zijn en ooit de start-up fase voorbij zal komen. Is er bovendien nog wel ruimte voor nog een nieuw repository (zie ook de lijst bovenaan)? In elk geval betreft het een open source systeem om de komende jaren in de gaten te houden.
De opening keynote werd dit jaar verzorgd door Casey Fiesler. Haar presentatie met als titel “Growing Their Own: Building an Archive and a Community for Fanfiction” focuste op de rol van de gemeenschap in digitale duurzaamheid. De website Archiveofourown.org (AO3) is opgezet ter vervanging van Live Journal en FanLib, twee grote platformen voor fanfiction schrijvers. Om verschillende redenen voelden gebruikers zich hier niet meer welkom. Ze hadden behoefte aan een “Space of their own, met als resultaat AO3; met 1,5 miljoen gebruikers en 0,5 miljoen werken een substantiële community. AO3 heeft vooral een archief-functie, dus alle social media activiteiten vinden plaats buiten het archief, zoals in Tumblr. Bijzonder is dat de site bijna geheel bedacht, gebouwd en beheerd wordt door vrouwen. Fiesler onderzocht deze community en stelde vast dat AO3 voor een groot deel user-driven is:

Iconen in AO3
Belangrijkste advies van Fiesler: ook andere communities, zoals die van de open source repository systemen zouden zich op deze manier kunnen organiseren, om zo hun voortbestaan te garanderen.
De rol van de gemeenschap in het toekomstbestendig maken van een repository zou gedurende de week verschillende keren voorbij komen, er was onder meer een volledige sessie aan gewijd. Dit speelt vooral bij nationale, regionale en thematische repositories, waar meerdere instellingen aan bijdragen. Allen stelden vast dat het lastig is om financiering te krijgen voor het onderhoud, dit is nu eenmaal geen sexy onderwerp. De presentaties lieten zien dat er op verschillende manieren werd gezocht naar een duurzaam business model. Sommige repositories zoals het Digital Repository of Ireland zijn overgegaan op het bieden van extra diensten voor betalende leden. Anderen zoeken het vooral in de inrichting van de organisatie: door activiteiten te decentraliseren (“many people doing little jobs”), zoveel mogelijk taken te automatiseren, vrijwilligers te motiveren etc. En misschien het allerbelangrijkste: onder het mom ‘niemand is onmisbaar’ ervoor te zorgen dat er niet één persoon eindverantwoordelijk is, maar te vertrouwen op het zelforganiserende vermogen van de gemeenschap.
Opvallend was dat maar weinigen een commerciële partner in de arm hadden genomen, “van de community, voor de community”, was steeds het uitgangspunt en advertenties hebben een negatief effect op de gebruikerservaring, met name op de betrouwbaarheid van een repository.
Bij Cornell university bleek in de loop der jaren een lappendeken aan repositories te zijn ontstaan. Een werkgroep heeft voor repository managers, administratie en marketing het Cornell University Library Repository Principles and Strategies Handbook opgesteld. Het beschrijft vooral wat er allemaal komt kijken bij het beheer van een repository, en wordt gebruikt wanneer onderzoekers zich melden met de vraag om een nieuw repository. Door hierover een beter bewustzijn te kweken hoopt men dat onderzoekers eerst kijken naar mogelijkheden om gebruik te maken van bestaande infrastructuren, en niet weer een nieuwe gaan bouwen. Het handboek is voor een veel grotere groep interessant. Het geeft bijvoorbeeld ook instructies voor een file directory in een dataset, filenaam conventies, software beschrijvingen en copyrights.
De Islandora Foundation heeft verschillende kanalen opgezet om de toekomst van het repository te garanderen. Dit alles onder vanuit de idee “The sustainability of software is rooted in the sustainability of a community. Zo hebben ze een betaald lidmaatschap opgezet (wij zijn als UBL sinds dit jaar collaborator) die deelname mogelijk maakt in de Coordinating Committee en Technical Advisory Group, er zijn zelf-regulerende interest groups rondom specifieke onderwerpen en Google discussiegroep voor vragen en kennisuitwisseling. Ook wordt er enkele keren per jaar een Islandora Camp georganiseerd: het eerstvolgende is van 20-22 juni in Limerick en een delegatie van UBL zal hier heen gaan om kennis uit te wisselen.
 Tijdens de Repositories Rodeo presenteren vertegenwoordigers van alle groter open resource systemen kort de laatste ontwikkelingen, waarna er gelegenheid is tot vragen. Dit zorgde ook dit jaar weer voor een levendige discussie. Je kon hierbij goed merken dat veel platforms van project of start-up fase naar volwassenheid zijn gegroeid. Ze zijn beter georganiseerd als organisatie, en werken op verschillende manieren samen, onder meer in de overgang naar Linked Data en RDF. Ook hebben ze samen meegeschreven aan de Guidelines voor Next Generation Repositiories die in november 2017 zijn verschenen. De vraag naar waar we over 5 jaar staan leverde een aardige samenvatting op van de conferentie:
Tijdens de Repositories Rodeo presenteren vertegenwoordigers van alle groter open resource systemen kort de laatste ontwikkelingen, waarna er gelegenheid is tot vragen. Dit zorgde ook dit jaar weer voor een levendige discussie. Je kon hierbij goed merken dat veel platforms van project of start-up fase naar volwassenheid zijn gegroeid. Ze zijn beter georganiseerd als organisatie, en werken op verschillende manieren samen, onder meer in de overgang naar Linked Data en RDF. Ook hebben ze samen meegeschreven aan de Guidelines voor Next Generation Repositiories die in november 2017 zijn verschenen. De vraag naar waar we over 5 jaar staan leverde een aardige samenvatting op van de conferentie:
Ook vanuit ons perspectief is dit laatste punt een actueel thema, want het heeft directe consequenties voor de inrichting van je infrastructuur. Kies je er met het oog op beheersbaarheid voor het aantal systemen zoveel mogelijk te beperken? Of kies je juist voor flexibiliteit, en zijn het de koppelingen die voor beheersbaarheid zorgen? Met andere woorden: gaan we proberen om alle wensen van onze eigen gebruikers in Alma& Islandora te verwezenlijken, of gaan we gebruik maken van verschillende, verbonden systemen?
Hoewel ik geen technische achtergrond heb, bezocht ik toch enkele sessies in de zogenaamde Developers Track. Het is interessant om te zien welke tools er zoal worden ontwikkeld, sommigen kunnen namelijk met kleine aanpassingen namelijk door ons worden hergebruikt. Terence Brady van Georgetown University Library presenteerde allereerst DSpace REST Reporting Tools die hij heeft ontwikkeld voor Dspace 5 of 6. Hiermee kun je o.a. de consistentie controleren en update files maken om metadata te repareren. Denk aan records met ontbrekende metadata, of 0 bitstreams. Volgens eigen zeggen werkt dit beter dan de search box in DSpace, of een open source tool als Open Refine.
Diego Pino, een van de ontwikkelaars die het actiefste bijdraagt aan de Islandora code, presenteerde een tool waarmee de ingest in Islandora kan worden vereenvoudigd. De Islandora Multi Importer (IMI), maakt gebruik van spreadsheets als input formaat gebruikt, waardoor iedereen ermee zou kunnen werken.
Links:
Hoewel publicatie repositories de overhand hebben op de OR conferentie, was er ook veel aandacht voor digitaal erfgoed. De UBs van Georgetown en Edinburgh voelden vorig jaar (net als wij) de behoefte om een start te maken met IIIF. Zij besloten om te beginnen met kleine aantrekkelijke collecties en zo ervaring op te doen. Interessante case study van Georgetown betrof een gedigitaliseerd archief uit de rechtenbibliotheek. In dit geval ontbraken de metadata op item niveau (die zitten namelijk alleen in de collectiebeschrijving). Door een inhoudsopgave in de viewer op te nemen hoefden ze niet met terugwerkende kracht metadata aan de items toe te voegen. Georgetown heeft een tutorial gemaakt voor het genereren van de manifesten.
Edinburg is nog een stap verder gegaan. Aansluitend op de digitalisering van de Scottish Session Papers hebben ze de catalogisering geautomatiseerd uitgevoerd op basis van de titelbladen. Zij hebben bovendien Alma en genereren de manifesten op basis van hun catalogiseersysteem. Hierna willen ze IIIF gebruiken voor de presentatie van de Mahabharata scroll, een laat 18de eeuwse rol van 75 meter lang, die in digitale vorm niet geschikt is voor traditionele viewers.
Dit riep in Edinburg wel de vraag op waar en hoe de manifesten beheerd moeten worden. Zijn dit ook objecten in het repository? En zo ja, wat voor identifiers krijgen ze dan? De UB van Toronto (Scarborough) kreeg eveneens met deze vraag te maken toen ze een manier zochten om annotaties te kunnen maken in Islandora. Omdat de standaard workflow van Islandora hiervoor niet voldeed hebben ze hiervoor een ‘web annotation utility module’ ontwikkeld, ook wel Annotorious genoemd. Hieraan zit een uitgebreid rechtensysteem gekoppeld, waarmee onder meer annotaties kunnen worden goedgekeurd. De annotaties worden als nieuwe objecten in het repository opgeslagen, met een eigen content model en metadata. Een dergelijke keuze betekent natuurlijk wel dat je erfgoed repository zich ontwikkelt tot data repository.
Ook interessant was de presentatie van Shanti Thompson over het Reuse project. Doel is het maken van een toolkit voor het meten van hergebruik van erfgoed data (d.w.z. al het gebruik buiten het kijken en downloaden in het repository om). Dit is ingewikkeld, omdat de metadata die bij een object horen tijdens hergebruik in bijvoorbeeld social media, vaak verdwijnen. Doordat erfgoedinstellingen niet weten hoe ze het hergebruik kunnen meten, of het personeel om dit te doen niet voorhanden is, zijn er maar weinig instellingen die dit doen. Een van de conclusies is dat vooral academische bibliotheken denken dat hun data alleen door academici worden gebruikt, in een wetenschappelijke context, maar dit blijkt een misvatting. Het indirecte gebruik is veel gevarieerder en door een groter publiek dan gedacht.
Er waren meer presentaties die het gebruik van het repository als onderwerp hadden. Zo onderzocht UNT Texas (een repository voor meerdere wetenschappelijke en erfgoedinstellingen in de regio) hoe gebruikers precies navigeren in hun repository. Dat bleek veel gevarieerder dan gedacht: wat wij als collectie beschouwen, hoeft niet altijd zo door gebruikers ervaren te worden. Zoeken en browsen wordt door elkaar gebruikt, over collecties en materiaal types heen. Interessant daarbij was dat tegelijk in het publicatie repository, naar scripties en naar erfgoed wordt gezocht. Gebruikers zijn blijkbaar in eerste instantie geïnteresseerd in een specifiek onderwerp. Wij hebben inmiddels al besloten om hiervoor twee verschillende “voorkanten” in te richten, maar misschien is toch nog iets om te heroverwegen? Zo zag ik dat verschillende andere repositories, zoals dat van Texas en Georgetown, eveneens een gezamenlijke ingang voor zowel erfgoed en publicaties heeft gebouwd. Tegelijk was de belangrijkste conclusie van het onderzoek van de Texanen : “Many people interact with our repository not through the front door (but through Google)”, dus je moet er vooral voor zorgen dat je hier vindbaar bent.
De stelling van Andrea Schuler, digital librarian van Tuffs university is dat je niet vroeg genoeg kunt beginnen met studenten te betrekken bij je repository. Zo creëer je bewustzijn voor open access, copyright, hergebruik en licenties in concrete alledaagse situaties. De meeste universiteiten nemen alleen scripties op, en zijn huiverig om de resultaten van bijvoorbeeld onderzoekscolleges als dataset op te nemen. Dit betekent niet dat alles de moeite van het bewaren waard is. Er is een workflow om de relevantie en kwaliteit van de data te garanderen. 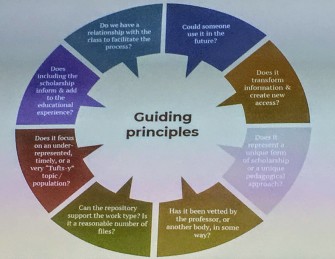 Schuler gaat zelf actief op zoek naar datasets die ze wil bewaren, zoals de resultaten van de Digital Design Studio, een ruimte voor digitale innovaties en projecten. Maar je kunt ook denken aan digitale tentoonstellingen van studenten kunstgeschiedenis. Ook blijft ze op de hoogte via de tips van vakreferenten.
Schuler gaat zelf actief op zoek naar datasets die ze wil bewaren, zoals de resultaten van de Digital Design Studio, een ruimte voor digitale innovaties en projecten. Maar je kunt ook denken aan digitale tentoonstellingen van studenten kunstgeschiedenis. Ook blijft ze op de hoogte via de tips van vakreferenten.
In diverse sessies kwam het gebruik van Linked Open Data binnen het repository aan de orde. Nieuwe generatie systemen zoals Samvera ondersteunen dit standaard. Islandora biedt dit aan in de vorm van Claw, de opvolger van de huidige installatie. Een mooi voorbeeld hiervan is de site die is ingericht voor het onderzoek naar zogenaamde Dragomans (1550-1750), vertalers, tolken en gidsen die in dienst waren van het Ottomaanse Rijk. De projectsite ziet er prachtig uit, je kunt vrijuit linken tussen personen, documenten, vertalingen en transcripties. Wel blijken de sites die zijn gebaseerd op Claw ook nog grotendeels “boutique sites” te zijn. Ik voorzie nog niet dat wij op korte termijn al onze data naar Claw moeten gaan overzetten (gelukkig, want we hebben de huidige migratie nog niet eens af….).
Mijn sessie had als onderwerp digital preservation (ik zat dit keer eens niet in een erfgoed-blokje). Hierdoor was de samenstelling gemengd, wat zowel voor- als nadelen heeft. Ook dit keer heeft iemand keurig notities gemaakt en in Drive opgenomen. De eerste presentatie was vooral technisch van aard en beschreef een tool voor het stroomlijnen van OAIS protocollen. Evviva Weinraub leidt momenteel een onderzoek naar de integratie tussen lokale repositories en gedistribueerde diensten (denk aan de content in ons eigen repository versus Delpher). Vragen die aan bod kwamen waren: hoe worden objecten geselecteerd voor opname in een van beide systemen, wat wordt waar op genomen (of gedupliceerd), hoe gaat men om met versiebeheer en interoperabiliteit? In de meeste gevallen worden meerdere kopieën bewaard, maar los van elkaar. Hiervoor blijken bovendien allerlei systemen te worden gebruikt.

In Amerikaanse UBs worden nog opvallend veel Homegrown systems gebruikt.
Een volledig rapport vind je hier:
https://arch.library.northwestern.edu/downloads/zk51vg841?locale=en
Mijn eigen presentatie ging over het duurzame beheer van een groeiend repository: hoe zorg je ervoor dat overstap naar grootschaliger en professioneel beheer soepel kan worden verlopen welke rol kan certificering hierbinnen spelen? Voor degenen die aanwezig waren bij de eindpresentatie van de stage van Federica Pugnali geen nieuw onderwerp, want tijdens deze gelegenheid hebben we hier ook al uitgebreid over gesproken.
De afsluitende Keynote was van Asaf Bartov, die zich zelf als open access activist profileert. Hij werkt voor de Wikimedia Foundation en hoewel hij dus geen bibliothecaris is, heeft hij tijdens de hele conferentie laten zien erg betrokken te zijn bij het onderwerp. Zo heeft hij op dag 1 een workshop gegeven over Wikipedia en was hij de gehele week aanwezig om te luisteren, discussiëren en ideeën op te doen. Tijdens zijn afsluitende keynote waande ik me even in Cuba: hij praatte met gemak 2 uur vol, en was zonder veel problemen ook de rest van de middag doorgegaan, maar dit liet ook wel wat zien over zijn betrokkenheid. Voor wie geïnteresseerd is, zijn gehele presentatie is hier te bekijken, of lees een samenvatting op papier. Zijn belangrijkste boodschap:
In veel instellingen zijn er al Wikipedians in residence en er wordt veel gebruik gemaakt van de kracht van crowdsourcing . Zo zijn met behulp van medisch specialisten de pathologie afbeeldingen van Calicut Medical college in India van metadata voorzien. Zoiets zouden wij natuurlijk ook kunnen doen met onze anatomische tekeningen.

Hebben bibliothecarissen meer problemen dan oplossingen? De Ideas Challenge leverde 100 user stories met problemen op, en maar 6 groepjes met een oplossing.
Elk jaar wordt er op OR ook een Ideas Challenge gehouden. Ik had nog niet eerder meegedaan, maar het leek me dit keer een mooie gelegenheid om met collega’s in contact te komen. Iedereen mag een probleem voorleggen in de vorm van een user story. In mijn geval heb ik beschreven dat de onderwerpstrefwoorden in ons repository vaak de lading niet dekken: onder meer doordat KIT KITLV en UBL een hele andere beschrijvingstraditie hebben, zijn vooral de foto’s van heel verschillende metadata voorzien. Dit zorgt voor een vertekend beeld bij gebruikers. Door op bv paard te zoeken denk je alle foto’s met een paard er op afgebeeld in je trefferslijst te krijgen, maar dat kan ook zomaar slechts een derde zijn, omdat KIT en KITLV dit trefwoord nooit hebben toegekend. Vervolgens mocht je met een zelf gekozen groepje een van de problemen kiezen en samen uitwerken tot een mogelijke oplossing. Aansluitend op de laatste keynote presenteerde elke groep de resultaten, en er waren natuurlijk coole (very nerdy) prijzen.

Mijn groep was heel divers, met een Amerikaan, een Amerikaanse Indiër, een Australiër en ikzelf, een mix van ontwikkelaars en (data-) managers. Wij hadden als taak om GDPR – zoals de rest van de wereld de nieuwe privacy wetgeving noemt – aan de man te brengen, zodat data-managers begrijpen wat er van hen wordt verwacht wanneer ze een dataset opnemen.
Hoewel we met onze presentatie niet wonnen (volgende keer meer inzet op de fun-factor!) had ik heel veel plezier gehad en drie nieuwe vrienden gemaakt. Bovendien voelde ik me alsnog een winnaar. Want van de 100 ingezonden vragen werd die van mij gekozen door de winnende groep (zie voor de presentatie met live demo hier). Zij stellen voor om IIIF en beeldherkenning hiervoor in te zetten. Op basis van de trefwoorden die wel zijn toegekend kun je door middel van software laten zoeken naar alle overige foto’s die ook een paard tonen, ook als is dit trefwoord niet toegekend. Dit zou een leuke pilot zijn voor het ontwikkelen van innovatie in de bibliotheek.
Volgend jaar wordt het hele circus iets dichterbij georganiseerd, namelijk in Hamburg. Het zou toch mooi zijn wanneer we dan met een wat grotere groep UBL collega’s aanwezig konden zijn, want niet alleen de prachtige Fedora T-shirts maken het de reis de moeite waard.
Klik hier om de (prettiger leesbare) pdf-versie op te halen.




Dit artikel verscheen in InformatieProfessional 2018/4 (informatieprofessional.nl).

Tijdens de jaarlijkse Open Repositories Conference worden de gebruikers en ontwikkelaars van open source digitale repository platforms wereldwijd samengebracht. De repositories worden voornamelijk gebruikt voor het bewaren, beheren en beschikbaar stellen van wetenschappelijke publicaties en gedigitaliseerd of digital born erfgoed. Dit kunnen instellingen zijn voor hoger onderwijs, maar ook overheid, bibliotheken, archieven en musea. Omdat we bij de UBL momenteel druk bezig zijn met het inrichten van een platform voor digitale bijzondere collecties, Digital Collections genoemd, is het voor ons extra belangrijk om hierbij aanwezig te zijn. Niet alleen om op de hoogte te blijven van wat er speelt, maar ook om te vertellen waar wij zelf staan. De conferentie wordt jaarlijks op een ander continent georganiseerd. Vorig jaar bezochten Laurents en ik de conferentie voor het eerst in Dublin. Dat was dus nog redelijk dicht bij huis. Maar dit keer reisden we naar de andere kant van de wereld, de 2017 editie was namelijk in Brisbane, Australië. Wij waren niet de enigen die ver hadden moeten reizen, want er waren 320 bezoekers uit 29 verschillende landen. Ook bijzonder: meer dan de helft presenteerde een paper of poster, of zat in een panel.
We arriveerden in de nacht van zondag op maandag en hoewel het in Brisbane momenteel winter is, was het naar onze maatstaven heerlijk weer. Dat hielp wel bij het verjagen van de jetlag. Maandag waren er nog geen sessies georganiseerd, maar konden we deelnemen aan een rondleiding langs diverse bibliotheekvestigingen van de University of Queensland, Queensland University of Technology, en Griffith University. Ik zag vooral veel experimenten met verschillende typen werkplekken en samenwerkruimtes, zowel binnen als buiten. Gedeelde ervaring: het is overal en altijd druk. En belangrijkste tip: zorg voor flexibele ruimtes en meubels op wielen die je makkelijk kunt verplaatsen, want de studenten zullen je voorzieningen zeker anders gaan gebruiken dan jij had bedacht.
Hoogtepunt was de recent verbouwde rechtenbibliotheek, oorspronkelijk een gebouw uit de jaren 30. Hier geen glas, metaal of heldere kleuren. De architect had bewust gekozen voor een sfeer die ergens lag tussen een herensociëteit uit de 19de eeuw en een Brits universiteitscollege. Een gebouw met een chique en tegelijk moderne uitstraling, met ruimtes die uitnodigden tot studeren. Het hele gebouw was 24/7 geopend, zonder dat dit problemen veroorzaakte. Blijkbaar is het zo dat wanneer je echt iets moois bouwt voor je studenten, ze ook bereid zijn om er zorgvuldig mee om te gaan. Omdat de studenten die deze week komen zeker nieuw zullen zijn stonden er drie behulpzame studenten bij de ingang met borden met “ask us” erop: zij helpen je op weg, wijzen de weg etc. Ook opvallend: er zijn overal waterpunten, en oplaadpunten voor laptops en telefoons.
Dinsdag stond in het teken van de pre-conference workshops. Het was Laurents gelukt om er zelfs aan twee mee te kunnen doen: in de ochtend Design thinking for open science innovation een methode waarmee aan verandering in organisaties vorm kan worden gegeven. In Noorwegen wordt deze methodiek door verschillende bibliotheken al volop gebruikt. Voorafgaand was de vraag gesteld om een complex vraagstuk aan te dragen. Bij datamanagement is een van de uitdagingen waar we voor staan op welke wijze gebruik gemaakt kan worden van commerciële dienstverleners zonder dat we de controle over de wetenschappelijke data verliezen, en zodoende niet terecht komen in eenzelfde situatie als het geval is met wetenschappelijke publicaties. Er is behoefte aan zogenaamde ‘rules of engagement’, d.w.z. regels waaraan commerciële partijen zich committeren zodat data voor wetenschappelijk onderzoek toegankelijk en bruikbaar blijven. Uit de inzendingen waren twee complexe vragen geselecteerd die door 5 groepen tijdens de workshop met behulp van Design Thinking methodieken werden aangepakt. De vraag van Laurents was er een van. Na een korte introductie over wat design thinking inhoudt (“Generally referred to as applying a designers’s sensibility and methods to problem solving, no matter what the problem is” (Lockwood, 2009)) werd er aan de hand van twee methodieken aan het werk gegaan. De eerste methodiek bestond uit het goed omschrijven van de vraagstelling met behulp van de stappen problem statement – participants – target users – scope – constraints – systems en goals. Vervolgens werden de drie belangrijkste elementen benoemd die cruciaal zijn voor een oplossing. Deze werden gevisualiseerd met afbeeldingen afkomstig uit papieren tijdschriften. De groep loste de vraagstelling niet op, maar de gestructureerde aanpak leidde wel snel tot inzicht over hoe de vraagstelling benaderd dient te worden.
In de middag vond workshop Hyku: Hydra in a box plaats, open source repository software voor instellingen die niet over een bataljon ontwikkelaars beschikken, maar toch van een flexibel repository systeem gebruik willen maken. Er zitten allerlei interessante API’s bij, zoals voor gebruik van IIIF, maar helaas is het nog (lang) niet af. Dit is overigens exemplarisch voor de stand van zaken voor veel open repository-systemen. Men worstelt om bij blijven. Dit bleek ook tijdens de update van de Islandora community. Hier wordt gewerkt aan de ontwikkeling van Islandora CLAW, waaraan tijdens Islandora Camp in Delft ook uitgebreid aandacht was besteed. Ook hier duurt het nog heel lang voordat er iets wordt opgeleverd waar instellingen mee aan de slag kunnen. En ondertussen moet er ook nog tijd, energie en aandacht worden besteed aan de “gewone” Islandora, want voor je het weet loop je hiermee weer hopeloos achter. Verder was er onder meer een presentatie door het repository-team van de Chinese University in Hong Kong. Zij gaan dit jaar nog over op Alma, en blijken te worstelen met de beschrijfregels voor Chinees en de synchronisatie met Islandora. Typisch een onderwerp waarin we samen op kunnen trekken. Zij beschikken over een vergelijkbaar (klein) team als wij in Leiden, en werken aan een repository van vergelijkbare omvang. Een hele geschikte partner om mee samen te werken dus en er zijn inmiddels al heel wat emails uitgewisseld met collega’s Jeff Liu en Louisa Lam. Hopelijk kunnen zij ons op hun beurt helpen om het inladen van de scans te versnellen, want zij hebben er inmiddels al meer dan 1 miljoen in zitten!

IIIF Workshop
De workshop die rondom IIIF was georganiseerd was voor natuurlijk niet helemaal nieuw meer (zie eerdere blogs hierover van Lucas van Schaik), maar toch de moeite waard om een keer heel uitgebreid uitgelegd te krijgen hoe IIIF in elkaar zit, en hoe de verschillende API’s werken. Erg leuk was dat we allerlei opdrachten kregen aan de hand waarvan de theorie telkens werd toegelicht. Ik kon daardoor voor het eerst zeggen dat ik het (echt!) snapte. Naast de standaard Image en Presentation API wordt er ook gewerkt aan de verdere ontwikkeling van Fulltext zoeken en Authenticatie. De laatste is vooral van belang om afbeeldingen te kunnen delen waar toegangsrestricties op zitten. Dat is niet alleen voor digitaal erfgoed van belang, onderdeel van de middag was ook een korte demonstratie van de werking van deze API voor publicaties in DSpace.
En verder hebben we ons vergaapt aan de prachtige faciliteiten van Queens University Faculty of Technology. Zo beschikte men over een enorm scherm voor presentaties en visualisaties (ook de posters werden hiermee gepresenteerd), en er waren overal aangename werkplekken en samenwerkruimtes in verschillende vormen en maten. De campus lag heerlijk in het groen, aan de botanische tuin met bloeiende planten en exotische vogels. En we troffen zelfs een half-ondergronds Olympisch zwembad aan tussen de collegezalen. Jaloersmakend inderdaad….
De keynote op woensdag werd gegeven door Timoty Gowers, niet alleen bekend als wiskundige, maar ook actief in de open access beweging. Gowers verhaal genaamd Perverse incentives. How the reward structures of academia are getying in the way of scholalry communication and good science was vooral een persoonlijke schets over de ontwikkelingen in zijn eigen vakgebied op het gebied van open science (met name ArXiv.org en MathOverflow). Niet heel spannend of vernieuwend, wel plezierig om naar te luisteren.
 Tijdens het bijwonen van de panel sessie van de Confederation of Open Access Repositories COAR Next Generation Repositories: Results and Recommendations kreeg je een helder overzicht gepresenteerd van de uitdagingen waar instellingen die een repository beheren mee te maken hebben.
Tijdens het bijwonen van de panel sessie van de Confederation of Open Access Repositories COAR Next Generation Repositories: Results and Recommendations kreeg je een helder overzicht gepresenteerd van de uitdagingen waar instellingen die een repository beheren mee te maken hebben.
Belangrijkste doel voor de toekomst is het creëren van repositories die interoperabel zijn, waarop vervolgens allerlei andere diensten kunnen worden gebouwd, zoals notificaties, global sign-on etc. Dit lijkt voor de hand liggend, maar is voor instellingen met kleine budgetten een grote uitdaging. Hiertegenover staan bovendien de commerciële partijen, waar de budgetten groot zijn en men dus consequent voorop loopt, en niet per se belang hierbij hebben. Om die reden worden de ontwikkelingen door gebruikers dan ook niet direct als een innovatie beschouwd, maar eerder als een noodzakelijkheid. Dit werd nog eens bevestigd door het verhaal van Chris Bourg, bibliothecaris van MIT. Waar COAR de internationale visie op repositories laat zien, toont Bourg in de Task Force on the Future of Libraries Preliminary Report de lokale visie.
Wat was er verder zoal te zien tijdens de reguliere sessies? In de sessie Discovery & Visualisation liet Tomasz Neugebauer aan de hand van e-Artexte, een repository voor contemporaine kunst, zien hoe netwerk visualisaties “serendipity discovery” kunnen stimuleren. Aan de hand van de metadata krijg je bijvoorbeeld een goed beeld van welke kunstenaars en curatoren met elkaar samenwerken. Een groep ontwikkelaars van CORE (een aggregator voor open access publicaties) ging dieper in op de zin en onzin van aanbevelingen in het repository. Het was grappig om te zien dat onderzoekers aanbevelingen niet altijd waardeerden, bijvoorbeeld omdat ze van een concurrent kwamen. Om deze reden hadden ze een knopje toegevoegd, waarmee onderzoekers konden aangeven dat de aanbeveling niet relevant was. Erg interessant in relatie tot digitale bijzondere collecties vond ik de presentatie van Northeastern University: Using WordPress to Contextualize and Publish Digital Repository Content. Hun Digital Scholarship Group werd (net als wij) steeds vaker geconfronteerd met de wens van onderzoekers om de resultaten van hun onderzoek via een webpresentatie te delen met de buitenwereld. Hiervoor ontwikkelden zij een gebruiksvriendelijke Exhibit Toolkit gebaseerd op WordPress. Deze plugin is gebouwd op het eigen Fedora/Hydra repository en werkt ook ook op DPLA. Ook de image API van IIIF is geïntegreerd. Onderzoekers kunnen hieruit objecten selecteren en zo heel eenvoudig webtentoonstellingen maken, terwijl tegelijk het duurzame beheer van de objecten kan worden gegarandeerd.
Wat duidelijk werd tijdens de conferentie, met name de sessie Managing images is dat veel repositories zich bezighouden met de integratie van IIIF, maar dat in veel gevallen alleen de image API wordt gebruikt, en/of dat alles buiten het repository is gehouden.

Scans vergelijken in het Sinai Palimpsest Project
Het is vooral nog een kwestie van experimenteren, net als bij ons in Leiden. Een erg mooi voorbeeld hiervan is het Sinai Palimpsests Project, een onderzoeks- en onderwijs omgeving voor 100 palimpsest handschriften uit de bibliotheek van het Sint-Catharinaklooster op het schiereiland Sinaï in Egypte. Met behulp van het IIIF framework en de Mirador viewer is een onderzoeksomgeving ingericht voor de bestudering van het materiaal. Ze hebben hiervoor van elk fragment meerdere soorten scans gemaakt, waaronder met multispectrum imaging. Vervolgens kun je verschillende versies met elkaar vergelijken. Er zijn ook allerlei handige tools toegevoegd, waaronder een meeschalende centimeter.
In de sessie over Innovations in open science werd de interessantste paper gegeven door Heli Kautonen van de National Library of Finland. Zij was eveneens verantwoordelijk voor de Design Thinking for Open Innovation workshop op dinsdag. Zij heeft de design principes toegepast op het inrichten van de access restricties in Finna, de Finse digitale bibliotheek. Basis vormt de identificatie van de gebruiker en het ultieme doel, en het vaststellen van de design principes voor de betreffende case. Een van de resultaten is dat in de facetten een specifieke vorm van access kan worden gekozen (bijvoorbeeld helemaal open, of alleen na inlog): zie links de facetten van de zoekterm “trial”: https://www.finna.fi/Search/Results?lookfor=trial&type=AllFields&limit=20&sort=
Op donderdagmiddag waren wij zelf aan de beurt en gaf ik onze presentatie over modellen voor samenwerking tussen het CDS en I&P. De presentatie maakte deel uit van de sessie Cultural heritage. Walters Art Gallery is een van de voorlopers op het gebied van open access van digitaal erfgoed. Bij zijn overstap van de Walters naar de University of Pennsylvania nam William Noel ook dit gedachtengoed met zich mee. Resultaat is de OPenn filosofie, zoals spreker Doug Emery vertelde in zijn paper. De bibliotheek beschikt op dit moment nog niet over een fancy infrastructuur en discovery interface (hier wordt wel aan gewerkt- een Fedora/Samvera omgeving). Wat ze doen is eenvoudigweg de mappenstructuur zichtbaar maken, en toegang geven tot alle files, dus ook de TIF archiefkopieën. Ook kunnen gebruikers (zowel mens als machine) CSV files met metadata downloaden. Simpel en goedkoop dus. Jammer genoeg kunnen ze ook geen goede statistieken genereren, want ik zou heel graag willen weten wie de gebruikers zijn, wat ze downloaden en welk percentage de OPenn op de hoogte stelt van gebruik van de files voor publicaties. In elk geval een voorbeeld dat navolging verdient.
 Ook interessant was de paper over Reverse Image Lookup, waarvoor aan de hand van de module “teaching with primary resources” van de Library of Congress het hergebruik van afbeeldingen werd onderzocht. Wat blijkt: de afbeeldingen (meest omslagen van boeken) werden helemaal niet exclusief gebruikt in het lager onderwijs. Slechts 10 % werd educatief hergebruikt, de rest bestond uit privé/persoonlijk hergebruik op social media en in blogs. Dat maakt dat je wel even gaat nadenken over wat nu echt je gebruikers zijn, en waar ze zich bevinden. Of is het zoals Open Knowledge oprichter Rufus Pollock schreef: “the best thing to do with your data will be thought of by someone else”
Ook interessant was de paper over Reverse Image Lookup, waarvoor aan de hand van de module “teaching with primary resources” van de Library of Congress het hergebruik van afbeeldingen werd onderzocht. Wat blijkt: de afbeeldingen (meest omslagen van boeken) werden helemaal niet exclusief gebruikt in het lager onderwijs. Slechts 10 % werd educatief hergebruikt, de rest bestond uit privé/persoonlijk hergebruik op social media en in blogs. Dat maakt dat je wel even gaat nadenken over wat nu echt je gebruikers zijn, en waar ze zich bevinden. Of is het zoals Open Knowledge oprichter Rufus Pollock schreef: “the best thing to do with your data will be thought of by someone else”
Op vrijdagochtend liet iedereen die zich bij Queensland University in Brisbane bezig houdt met research support zien hoe men onderzoeks-ondersteuning biedt door de gehele cyclus: van digitalisering, via Research Data Management en Scholarly Publishing tot aan Research Output & Impact. Een interessant voorbeeld van een keten-proces in de bibliotheek, een onderwerp dat ook bij ons in de UBL actueel is. Want hoewel de verantwoordelijken niet afkomstig zijn uit dezelfde afdeling, werd naar de gebruiker toe gestreefd naar een zogenaamde “seamless experience”. Basis voor de keten vormt het repository ESpace, waarin de digitale bijzondere collecties en de publicaties samen zijn opgeslagen. Dit is een bewuste keuze, en het maakt dat je gaat nadenken over het verschil tussen digitale (bijzondere) collecties en wetenschappelijke data (misschien is er wel geen verschil….)
Door de hele keten hieromheen op te bouwen, weet je al vanaf het begin waar de onderzoeker zich mee bezig gaat houden, je hebt hem als het ware al bij de hand genomen. Ook kan op die manier worden gestimuleerd dat onderzoekers hun data in het repository opnemen, en niet voor een externe voorziening kiezen. Want ze bieden aan het begin en eind van de cyclus ook metrics aan, onder meer voor het meten van de impact. Hiermee kunnen onderzoekers hun eigen meerwaarde aantonen. De identifier in ESpace is hiervoor essentieel. Relevant blijven is de belangrijkste uitdaging voor het team. Hoe zorg je ervoor dat je onderzoeker niet liever hetzelfde doet in een zelf gekozen repository? Dat kan alleen wanneer het voor onderzoekers makkelijker en plezieriger is om met de eigen bibliotheek samen te werken. De juiste mensen en voldoende budget zijn hiervoor essentiële factoren.

Rondleiding door de bibliotheek van Queensland University
Op de laatste middag kregen wij samen met de collega’s uit Hong Kong een Behind the Scenes rondleiding door de bibliotheek van Queensland University, waaronder de digitaliseringsafdeling en het CDS. Deze was georganiseerd door Tina Macht, alumnus van Book & Digital Media Studies in Leiden (op de foto in het midden, vandaar de universiteit Leiden trui!) die drie jaar geleden naar Brisbane is geëmigreerd en nu werkt voor het digitaliseringscentrum. Omdat outsourcen van digitaliseringsactiviteiten in een land als Australië minder voor de hand ligt, beschikken ze over uitgebreide voorzieningen, zoals een eigen fotostudio, en twee mooie Treventus robotscanners.
 Ook kregen we een uitgebreide tour langs de verschillende bibliotheeklocaties, waar we ons vergaapten aan de faciliteiten. Zo waren er overal fonteintjes en watertaps, en troffen we in elke bibliotheek een kitchenette aan, waar de studenten hun eigen eten in de koelkast konden bewaren, opwarmen in de magnetron en een kop thee konden zetten. En omdat veel vestigingen 24/7 open zijn, waren er zelfs relax fauteuils aanwezig, waar studenten even een power nap konden doen. En nee, er lag geen beschimmelde kaas in de koelkast (hebben we gecontroleerd) en de boeken waren niet besmeurd met spaghetti in tomatensaus. De baliemedewerkers bevestigden dat de studenten aan het begin van het semester altijd even moeten worden “opgevoed” en dat er hierna best wel eens een ongelukje kon gebeuren, maar dat het reuze meeviel met de rommel.
Ook kregen we een uitgebreide tour langs de verschillende bibliotheeklocaties, waar we ons vergaapten aan de faciliteiten. Zo waren er overal fonteintjes en watertaps, en troffen we in elke bibliotheek een kitchenette aan, waar de studenten hun eigen eten in de koelkast konden bewaren, opwarmen in de magnetron en een kop thee konden zetten. En omdat veel vestigingen 24/7 open zijn, waren er zelfs relax fauteuils aanwezig, waar studenten even een power nap konden doen. En nee, er lag geen beschimmelde kaas in de koelkast (hebben we gecontroleerd) en de boeken waren niet besmeurd met spaghetti in tomatensaus. De baliemedewerkers bevestigden dat de studenten aan het begin van het semester altijd even moeten worden “opgevoed” en dat er hierna best wel eens een ongelukje kon gebeuren, maar dat het reuze meeviel met de rommel.
Achter de linkjes in de tekst vind je telkens de bijbehorende foto’s. Wil je de complete set bekijken? Kijk dan op Flickr: https://www.flickr.com/photos/saskiavanbergen/albums/72157682679715802
Saskia van Bergen

Van 13 tot en met 15 juni 2017 werd het Islandora Camp in Delft gehouden. Een Islandora Camp is een bijeenkomst van gebruikers van Islandora (een digitaal repository) waar presentaties, workshops en tutorials gehouden worden door de Islandora Foundation en ook de gebruikers zelf. Ook wordt er veel gepraat en vooral kennis gedeeld tussen alle gebruikers van Islandora, wat ook dit keer weer heel zinvol was. Vanuit Leiden waren we met een (zware) delegatie van 4 personen: Wouter Kool van de faculteit Archeologie, Liesbeth van Wijk en Niels Molenaar van Digitale Diensten, en ik.

De eerste dag werd uitgelegd wat Islandora nu eigenlijk is, wat je ermee kan, hoe je kan bijdragen en wat er in de (nabije) toekomst gaat gebeuren. Elk jaar wordt bij de uitleg van wat islandora is de Islandora hamburger erbij gehaald. Het ene jaar is het plaatje wat mooier dan het andere jaar maar het komt erop neer dat Islandora als hamburger tussen de broodjes “Fedora” (de DAM architectuur, waar de digitale objecten worden bewaard) en “Drupal” (het CMS, die de presentatie van de digitale objecten doet) in zit. Er zijn dan verschillende toppings op de hamburger mogelijk, waaronder Solr (een zoek platform). Aangezien Solr vaak als de kaas van de hamburger wordt afgebeeld en eigenlijk een standaard component is, wordt tegenwoordig ook wel gesproken van de “cheeseburger”.
Islandora kan uitgebreid worden op verschillende manieren, oftewel er zijn verschillende toppings mogelijk. Voor verschillende types content zijn er solution packs beschikbaar, zoals voor plaatjes, boeken, video, pdf, enzovoorts. Maar als je content van een ander type in Islandora wil zetten, dan is dat mogelijk door een eigen solution pack hiervoor te ontwikkelen. Ook kan de functionaliteit uitgebreid worden door een module te installeren of zelf te maken. Het uiterlijk kan helemaal aangepast worden door in Drupal een theme te installeren of zelf te maken.
Islandora is een erg flexibel, modulair, aanpasbaar en uitbreidbaar repositorium en biedt dus veel mogelijkheden om naar eigen wens aan te passen, uit te breiden en te verbeteren. Hiervoor is echter wel veel kennis nodig en die konden we voor een deel opdoen tijdens dit camp.
Er werd ook uitgebreid stilgestaan bij de toekomst; de broodjes (Fedora en Drupal) hebben namelijk allebei een nieuwe versie die nogal verschilt van de versie die de huidige Islandora gebruikt, en daarom wordt er hard gewerkt aan een nieuwe versie van Islandora. Deze nieuwe versie staat bekend onder de naam Islandora CLAW. Deze kan ook niet meer als een hamburger gerepresenteerd worden, aangezien de verschillende onderdelen op een andere manier met elkaar omgaan. Islandora zelf is geen laag meer hierin, maar integreert in elk onderdeel en speelt daarin verschillende rollen. Als er iets gebeurt in een onderdeel (bijvoorbeeld een nieuwe digitaal object wordt ingelezen in Fedora), dan worden andere onderdelen daarvan via events op de hoogte gebracht waarop zij kunnen handelen (bijv. Solr doet indexering). Door deze asynchrone manier van werken lijken acties veel sneller uitgevoerd te worden, omdat er niet meer op gewacht hoeft te worden. Eigenlijk wordt alleen maar gezegd dat een actie uitgevoerd moet worden en het systeem handelt dit dan af op het eerste beschikbare moment.
Ook wordt het onderliggende data model gewijzigd. Aangezien Fedora 4 alle data opslaat als RDF en via Linked Data communiceert, is er hiervoor (dit is dus meer omvattend dan Islandora alleen) een nieuw data model ontwikkeld genaamd het Portland Common data model. Dit is een uitbreidbaar, flexibel domein model dat als basis moet dienen voor veel DAMS.
Een mooie ontwikkeling is het plan is om binnen Islandora CLAW IIIF te gaan ondersteunen. Wanneer dit ontwikkeld wordt en in welke mate, bleef echter nog even onduidelijk, maar er zijn wel concrete plannen voor.
Islandora CLAW wordt op dit moment ontwikkeld. Een eerste minimale versie staat gepland voor eind juni 2017, maar dat is zeker geen versie die al gebruikt kan gaan worden. Dit is absoluut iets om in de gaten te houden, maar niet iets waar we concreet mee aan de slag kunnen op korte termijn.
In de huidige Islandora versie zijn er ook genoeg ontwikkelingen. Hieronder een korte beschrijving van de meest interessante:
Het Oral History Solution Pack maakt het mogelijk om audio en video in Islandora in te laden. Op zich was dit al mogelijk, maar nu kunnen ondertitels en transcript er ook bij ingeladen en afgebeeld worden. Binnen de ondertitels en transcripts kan gezocht worden, zelfs op de naam van de spreker.
May Bragdon Diaries is een Islandora site die de moeite waard is om te bekijken. De site bevat 10 dagboeken die volledig doorzoekbaar en geannoteerd zijn. Via links kan men meer te weten komen over de verschillende personen en objecten, die allemaal bekend staan onder verschillende namen. Sommige bladzijdes bevatten krantenknipsels, foto’s of ansichtkaarten en deze zijn als geheel maar ook los gescand en dus te bekijken. Deze site laat goed de kracht en flexibiliteit van Islandora zien, maar ook dat zoiets veel werk is (een projectteam van 10 personen heeft hier 5 jaar aan gewerkt).
Natuurlijk werden er andere leuke Islandora sites ook getoond; katten, honden, geneeskunde, violen en St. Andrews. Ook werden er veel (nieuwe) Islandora modules getoond, allemaal te vinden via Islandora awesome. Zo is er een EAD solution pack, een Serial solution pack, een Document solution pack (waarmee Office documenten ingeladen kunnen worden), een Binary solution pack (alle bestandstypes maar zonder een manier om die te tonen), een XML solution pack (XML bestanden ingelezen in Islandora kunnen met een XSL transformatie getoond worden) en een Streaming media solution pack (kan MP4 video bestanden die ergens anders zijn opgeslagen via Islandora streamen naar de gebruiker).
Op dag 2 was er een dev track en een admin track. Ik heb de dev track gevolgd, waarin van alles werd besproken en veel vragen beantwoord werden. Zo heb ik weer wat nieuws geleerd over SOLR en XACML die beide belangrijk zijn binnen Islandora. Al deze dingen waren heel leerzaam voor mij, maar helaas niet heel geschikt om in een blog over te schrijven. Wel bleek er iemand bezig te zijn met een IIIF module voor de huidige versie van Islandora. Deze module is nog in ontwikkeling maar is wel interessant om dit te volgen en wellicht hieraan bij te dragen.
Op de derde en laatste dag werden als eerste zoals gebruikelijk de “Islandora Camp awards” uitgereikt. Dit zijn prijzen voor degene die het verst gereisd heeft, die het meest betrokken was bij het camp enzovoorts. Deze prijzen zijn een ludiek en terugkerend thema op de Islandora Camps.
De derde dag was ook de dag van de presentaties. Er werd door een aantal gebruikers van Islandora een presentatie gegeven over hoe zij Islandora gebruikten en/of hadden aangepast aan hun wensen. Een van de mensen was ik. In mijn presentatie heb ik uitgelegd hoe wij de data van onze oude systemen in ons nieuwe Islandora repositorie importeren. Het probleem is namelijk dat de data die geëxporteerd wordt uit deze oude systemen, niet in een formaat staat wat ingelezen kan worden door Islandora. En aangezien we meerdere oude systemen hebben die allemaal meerdere eigen formaten exporteren, is dit een groot probleem. Hiervoor heb ik een module (Prepare Ingest) gebouwd waarmee een workflow gemaakt kan worden waarmee de data van het ene formaat in een formaat wat Islandora in kan lezen, omgezet kan worden. Tijdens de presentatie demonstreerde ik dit met een relatief simpele export van plaatjes die meerdere boeken representeerden. Gelukkig ging dit allemaal goed.
Als de data is omgezet met deze module, kan het ingelezen worden in Islandora. Deze maakt er dan automatisch afgeleiden van. Aangezien dit niet altijd goed gaat en we een mogelijkheid wilden hebben om te controleren of een importeeractie goed was gegaan, heb ik een module (Check datastreams) gemaakt die controleert of alle objecten compleet zijn. Deze module heb ik ook gepresenteerd.
Metadata wordt bij ons in Alma geregistreerd. Natuurlijk willen we deze metadata ook binnen Islandora gebruiken. Ik heb hiervoor een module (Metadata synchronisation) gemaakt die metadata van een OAI-PMH bron kan ophalen en gebruiken binnen Islandora. Ook deze module heb ik op het Islandora Camp gepresenteerd. Mijn volledige presentatie is hier te vinden.
Na mijn presentatie was er nog een presentatie van de man die de meeste lovende woorden over mijn modules had. Hij (Diego Pino Navarro) presenteerde zijn eigen module de Multi Importer. Hiermee kunnen objecten van verschillende types tegelijkertijd ingelezen worden in Islandora. Deze module heeft voor een deel soortgelijke functionaliteit als mijn module Prepare Ingest. We hebben nog hierover gepraat en vonden het allebei een goed idee om meer naar elkaars werk te kijken en wellicht delen van elkaars werk in het eigen werk op te nemen. Dit is dus nog een van de dingen die op mijn to do lijstje staat.
Islandora Camp eindigde met een unconference; oftewel stel alle vragen die je nog hebt en dan proberen we samen een antwoord te vinden. Dat hebben we natuurlijk gedaan en onze vragen werden ook allemaal beantwoord. Dit was echter wel een conferentie waar je vandaan komt met een heel pak huiswerk; ik moet nog veel dingen bekijken, nader uitzoeken en vooral heel veel lezen. Dus ik ga nu maar weer ’s aan mijn huiswerk!





