
Regionaal Historisch Centrum Limburg in Maastricht, gevestigd in de oude Minderbroederskerk
Op 2 en 3 februari vond in het Regionaal Historisch Centrum Limburg in Maastricht de internationale conferentie Parchment, Paper and Pixels. Medieval Writing and Modern Technology plaats. De bijeenkomst werd georganiseerd door SSNM (Schrift en Schriftdragers in de Nederlanden in de Middeleeuwen), het Huygens Instituut voor Nederlandse Geschiedenis, het RHCL en het Henri Pirenne Instituut voor Middeleeuwse Studies te Gent. Hoewel de titel doet vermoeden dat de presentaties alleen paleografie en oorkondeleer als onderwerp hadden, was de scope breder dan dat. Het doel van de conferentie was om de relatie tussen de Middeleeuwse en digitale wetenschappen in het algemeen te analyseren. Mediëvisten die op geen enkele manier gebruik maken van digitale hulpmiddelen zullen dun zijn gezaaid, alleen al de aanwezigheid van gedigitaliseerd handschriftelijk materiaal op het web heeft het onderzoek de laatste decennia veel toegankelijker gemaakt. Maar voor Digital Humanities onderzoek is wel wat meer nodig. Tijdens het symposium werd een aantal succesvolle projecten gepresenteerd.
Opgeleid als Mediaevist ben ik uiteraard breed geïnteresseerd in de ontwikkelingen in mijn vakgebied. Maar vanuit mijn functie bij de UBL was het ook boeiend om te zien van welk type tools onderzoekers op dit moment gebruik maken bij hun onderzoek, welke behoeften spelen, en bij welke onderdelen van het onderzoeksproces de bibliotheek een rol kan spelen.
De keynote op de eerste dag werd verzorgd door Peter Stokes. Hij is de bedenker van DigiPal, een open source tool voor het vergelijken van schrift. De software stelt onderzoekers in staat om te zoeken naar lettervormen, en de karakteristieke kenmerken eenvoudig met elkaar te vergelijken. Je kunt bijvoorbeeld letters over elkaar schuiven, en ze op een tijdlijn zetten. Hoewel Stokes DigiPal oorspronkelijk ontwikkelde voor Engels elfde-eeuws schrift, wordt de software inmiddels breder toegepast, met als resultaat SephardiPal (Hebreeuws schrift van het iberisch schiereiland), ScandiPal (het schrift van Scandavische fragmenten) en BayeuxPal (lettervormen op het tapijt van Bayeux).
In het verleden werd er nog wel eens getwijfeld aan de status van paleografie en codicologie: was het niet eigenlijk een hulpwetenschap voor historici? De DigiPal tool maakt het werk van de onderzoeker makkelijker, maar neemt het niet uit handen. DigiPal vertelt je niet of handschrift A en B door dezelfde kopiist zijn geschreven of niet, de interpretatie moet nog altijd van de onderzoeker zelf komen. Toch bestaat de angst dat tools als DigiPal er op den duur voor zorgen dat de rol van de paleograaf helemaal verdwijnt, en op basis van kwantitatieve analyses ook de conclusies kunnen worden getrokken. Dit was precies het onderwerp van de paper van Mats Dahllöf, die zich bezighoudt met automatische toeschrijving. In zijn abstract claimt hij een nauwkeurigheid van 97,1 % te bereiken, maar helaas moest hij door ziekte afzeggen. Natuurlijk wordt pas door de juiste vragen, methode en analyses van de onderzoeker software een echte onderzoekstool. Tegelijk vereist het andere kwaliteiten van de onderzoeker. Is het ook nodig dat zij zich al deze nieuwe technieken eigen maken? Tot op welke hoogte? En hoe komen ze aan deze kennis?
Miriam Edlich-Muth houdt zich bezig met de verspreiding van Floris ende Blancefloer. Van deze tekst zijn vele versies en vertalingen gemaakt, en het verhaal is dan ook van Griekenland tot en met IJsland bekend. Zoals veel onderzoekers begon zij met het vastleggen van kwantitatieve gegevens in een spreadsheet, maar al snel realiseerde ze zich dat deze methode niet voldeed aan haar wensen. Met behulp van een ontwikkelaar op haar afdeling maakte ze enkele zogenaamde heatmaps en dendrogrammen (voor het maken van een hiërarchische cluster analyse), tools die veel worden gebruikt door statistici. Uit diverse papers bleek dat onderzoekers op verschillende niveaus hulp kunnen gebruiken bij Digital Humanities onderzoek. In de eerste plaats bij het kiezen van de juiste tool. Hiltmann & Gniffke wilden bijvoorbeeld TEI gebruiken om de ontwikkeling van de Franse tekst “Comment les obseques se doivent faire”, over de uitvaart van edelen, in kaart te brengen. Als snel kwamen ze erachter dat de standaard hiervoor voldeed. TEI is een xml standaard bedoeld voor het maken van digitale edities en te plat voor het visualiseren van relaties tussen teksten. Ook wilden ze allerlei zaken in de standaard stoppen die er eigenlijk helemaal niet in thuis horen, en waar waarschijnlijk veel betere tools beschikbaar voor zijn. Precies hierin kan een Centre for Digital Scholarship een belangrijke rol spelen. Hier beschikt men over een overzicht van de beschikbare tools en technieken in de diverse vakgebieden en de toepassingen tot dat moment. Software die binnen het ene vakgebied is ontwikkeld om taken te automatiseren, kan in het andere vakgebied geschikt zijn om nieuwe onderzoeksvragen te beantwoorden. Ook kan een dergelijk loket een rol spelen bij het samenbrengen van onderzoekers uit verschillende disciplines. Het onderzoek van Stephen Smith en Deborah Thorpe liet zien waar een dergelijke samenwerking toe kan leiden. Smith houdt zich bezig met de ontwikkeling van medische hulpmiddelen voor patiënten met neurologische aandoeningen, en Thorpe is paleograaf. Samen onderzochten zij neurologische aandoeningen in de middeleeuwen aan de hand van (handgeschreven) teksten. Een bekend voorbeeld hiervan zijn de teksten van de 13de eeuwse Tremulous hand of Worcester, herkenbaar aan zijn bevende schrift. Opvallend is dat veel kopiisten, waaronder de Tremulous hand, ondanks hun conditie nog heel lang door konden schrijven. De onderzoekers wilden achterhalen aan welke aandoening zij leden. Was het mogelijk de ziekte van Parkinson, of toch Alzheimer?

Ook het magische woord IIIF kwam een aantal keer voorbij. Verschillende onderzoekers lieten weten dat ze staan te springen om de mogelijkheden van het protocol te gaan gebruiken. Ze willen bijvoorbeeld gedigitaliseerde handschriften over een specifiek onderwerp op één plek samenbrengen om ze beter te kunnen vergelijken, of gedigitaliseerde handschriften transcriberen en annoteren, zoals wordt gedaan in French Renaissance Paleography.
Agata Dierick vertelde over Itinera Nova, een voorbeeld van een succesvol crowdsourcings-project geïnitieerd door het stadsarchief van Leuven. Doel is het digitaliseren en ontsluiten van de registers van de Leuvsense schepenbank (1362-1795). Aangezien het bijna een half miljoen folia betreft, heeft men hiervoor de hulp van vrijwilligers ingeroepen. Hiervoor werd een online platform ingericht met handleidingen, filmpjes en mogelijkheden voor kennisuitwisseling. Ook werd een interactieve online tutorial paleografie ontwikkeld.
De keynote op de tweede dag werd gegeven door Georg Vogeler van de universiteit van Graz. Hij werkt hier als Digital Humanities specialist voor het ‘Zentrum für Informationsmodellierung in den Geisteswissenschaften’. Hij vertelde met name over de uitdagingen bij het integreren van twee charter databases: Regesta imperii en Monasterium.net. Regesta imperii heeft een tijd geleden de ruwe data vrij beschikbaar gesteld onder CC-BY licentie. Hierdoor was het mogelijk geworden om de dataset te integreren in Monasterium.net, een database platform dat zelf ook weer verschillende typen bronnen samenbrengt: gedigitaliseerde gedrukte edities, beschrijvingen en scans van charters en aanvullende data die alleen via de website beschikbaar wordt gesteld. Integratie levert niet alleen een betere vindbaarheid op, maar ook een verbetering van de functionaliteiten. Wat is hiervoor nodig?
- Meer datasets zouden open access beschikbaar moeten worden gesteld;
- Via een api met data in formats die uitwisseling bevorderen;
- Als linked open data met semantic web technologies;
- En door het gebruik van gedeelde conceptuele modellen
Allemaal zaken waar in Nederland dankzij de activiteiten van het NDE gelukkig al hard aan wordt gewerkt.
In zijn slotbeschouwing stelde Georg Vogeler vast dat onderzoek aan de ene kant steeds vaker interdisciplinair is, maar dat dit aan de andere kant ook weer eigen specialisaties aan het worden zijn. “ Hij vraagt zich dan ook af: are we narrowing down again?” Samenwerking en kennisdeling is noodzakelijk voor innovatie, dus de vraag is hoe dit kan worden voorkomen. Ook hierin kan volgens mij de bibliotheek (en met name een CDS) een rol spelen, doordat de kennis over tools en methodes hier niet alleen wordt verzameld en gedocumenteerd, maar ook weer wordt gedeeld. Dat kan door lezingen, conferenties en workshops, maar ook met een-op-een contact met onderzoekers. De bibliotheek kan op deze manier ook fungeren als motor voor innovatie.
Saskia
p.s. De tremulous hand bleek trouwens aan een essentiële tremor te lijden, d.w.z. zonder aanwijsbare oorzaak. Dat op sommige pagina’s het schrift een stuk minder bibberig is, komt volgens de onderzoekers doordat de kopiist ofwel heeft uitgerust, ofwel licht beschonken was. Een borrel was in de middeleeuwen dus niet alleen een beloning na het schrijven…





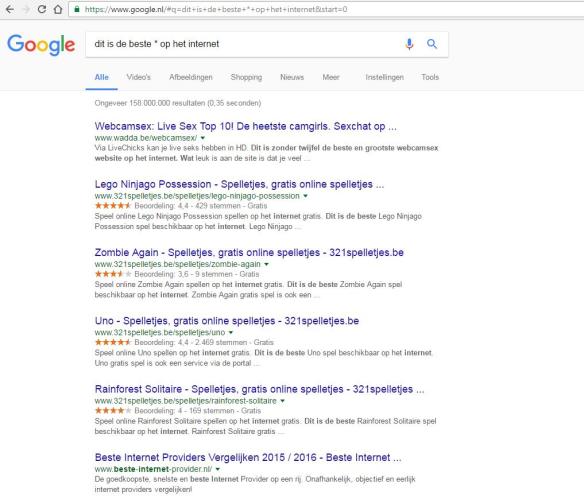



 Google is als een vaste partner: je bent er aan gewend, er treedt geleidelijk aan een zekere sleur op en je kent na verloop van tijd alle gebreken van de ander, maar toch blijf je trouw, al was het maar uit gewoonte. Daarom kan ik iedereen adviseren om af en toe eens vreemd te gaan. Met een zoekmachine uiteraard.
Google is als een vaste partner: je bent er aan gewend, er treedt geleidelijk aan een zekere sleur op en je kent na verloop van tijd alle gebreken van de ander, maar toch blijf je trouw, al was het maar uit gewoonte. Daarom kan ik iedereen adviseren om af en toe eens vreemd te gaan. Met een zoekmachine uiteraard.
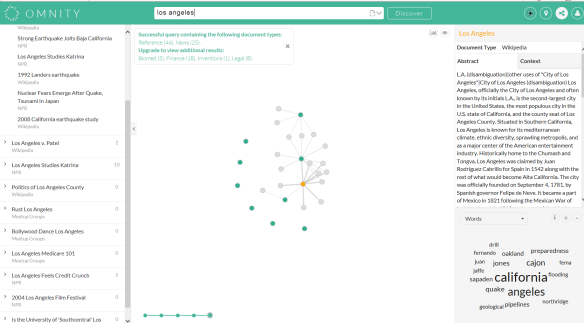
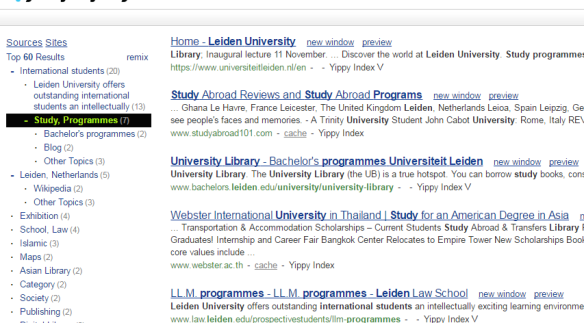
 Het was een trip down memory lane, mijn bezoek aan de Internet Librarian International Conference 2016 in het Olympia Conference Center in Londen. In 1999 was ik in hetzelfde zalencomplex voor een bezoek aan de Online Conference. De enige aanpassing die het Olympia sindsdien aan de moderne tijd had gedaan was de tassencontrole, maar daar was het in Londen niet bepaald uniek in. Voor mijn werkgever moest ik destijds een verslag schrijven en ik weet nog dat ik de naam van die nieuwe zoekmachine nog even moest nazoeken in mijn aantekeningen. Oh ja, Google.
Het was een trip down memory lane, mijn bezoek aan de Internet Librarian International Conference 2016 in het Olympia Conference Center in Londen. In 1999 was ik in hetzelfde zalencomplex voor een bezoek aan de Online Conference. De enige aanpassing die het Olympia sindsdien aan de moderne tijd had gedaan was de tassencontrole, maar daar was het in Londen niet bepaald uniek in. Voor mijn werkgever moest ik destijds een verslag schrijven en ik weet nog dat ik de naam van die nieuwe zoekmachine nog even moest nazoeken in mijn aantekeningen. Oh ja, Google. Begin september 2016 was ik bij het
Begin september 2016 was ik bij het 

