Als pdf (beter leesbaar).



Dit artikel verscheen in InformatieProfessional 2017/1 (informatieprofessional.nl)
Als pdf (beter leesbaar).
Dit artikel verscheen in InformatieProfessional 2017/1 (informatieprofessional.nl)
 Google is als een vaste partner: je bent er aan gewend, er treedt geleidelijk aan een zekere sleur op en je kent na verloop van tijd alle gebreken van de ander, maar toch blijf je trouw, al was het maar uit gewoonte. Daarom kan ik iedereen adviseren om af en toe eens vreemd te gaan. Met een zoekmachine uiteraard.
Google is als een vaste partner: je bent er aan gewend, er treedt geleidelijk aan een zekere sleur op en je kent na verloop van tijd alle gebreken van de ander, maar toch blijf je trouw, al was het maar uit gewoonte. Daarom kan ik iedereen adviseren om af en toe eens vreemd te gaan. Met een zoekmachine uiteraard.
Met Microsoft’s Bing (www.bing.com) bijvoorbeeld, dat ooit de grote tegenhanger van Google moest worden. Dat is nooit helemaal gelukt, maar volgens de gebruiksstatistieken is het wel een goede tweede. Vagin en peni (zie mijn vorige blog) vult hij keurig aan. De autocompletefunctie is over de hele linie trouwens wat beter dan die van Google. Wanneer je op een bepaald bestandstype wil zoeken, ben je bij Bing aan het goede adres: als je filetype:docx opgeeft, vindt hij zowel de nieuwe *.docx als de oudere *.doc bestanden. Hetzelfde geldt voor Powerpoint- en Excelfiles.
Als je absoluut niet wilt dat een zoekmachine je gegevens bijhoudt zijn er talloze alternatieven voorhanden. Duckduckgo ( duckduckgo.com) is bijvoorbeeld een heel aardige zoekmachine die je niet volgt. Een handige optie van Duckduckgo is dat je heel makkelijk van regio kunt veranderen. Als ik iets wil lezen over mijn neef, die schrijver is, schakel ik over naar zijn geboorteland Nieuw-Zeeland en vind hem al in de eerste zoekresultaten, terwijl ik daarvoor bij andere zoekopties flink moet doorscrollen. Maar het handigste van Duckduckgo zijn de bangs. Via deze optie kun je je zoekactie beperken tot één bepaalde krant, database, catalogus, site enz. Er zijn duizenden van die bangs en het aantal groeit.
Het Engelse Oscobo (https://oscobo.co.uk/) houdt evenmin persoons- of zoekgegevens bij. Je ziet wel advertenties, maar je krijgt niet tot in den treuren advertenties van boormachines te zien omdat je daar ooit een keer op hebt gezocht.
StartPage van IxQuick (https://www.startpage.com/) geeft je zoekopdracht door aan Google zonder dat jouw gegevens meegaan, ook je ip-adres niet. Hiermee kun je dus via een omweggetje gebruik maken van Google, zonder dat Google gebruik maakt van jou. Op die manier kun je ook anoniem de websites bezoeken die je via de zoekmachine vindt.
Ook bij het Franse Qwant (https://www.qwant.com/) staat privacy hoog in het vaandel. Het leuke van deze zoekmachine is de vormgeving. De zoekresultaten worden getoond in drie kolommen: internet, nieuws en sociaal. Een groot voordeel van Qwant is dan het helemaal geen advertenties heeft. Het geld komt binnen doordat het bedrijf de techniek verkoopt aan ondernemingen.

Het Zwitserse Hulbee (https://hulbee.com/) houdt evenmin persoonlijke gegevens vast. Er zijn wel op de persoon gerichte advertenties, maar die zijn gebaseerd op de huidige zoekactie. Hulbee heeft een mooie woordenwolk, waarmee je je zoekactie kunt verfijnen of verleggen. De machine wordt vooral geschikt bevonden voor publieke omgevingen omdat gewelddadige en pornografische content wordt geblokt.
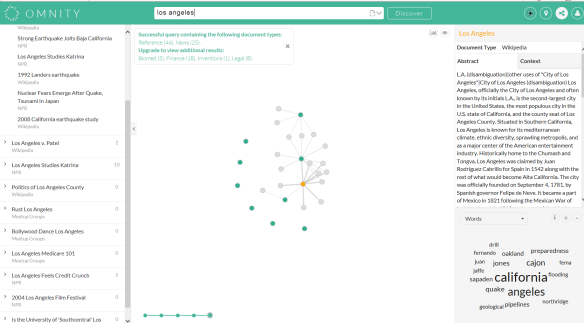
Omnity (https://www.omnity.io/) is een associatieve semantische zoekmachine met een grafische weergave. Het schijnt vooral bedoeld te zijn voor studenten en onderzoekers. Je kunt gewoon een zoekterm invullen, maar ook een volledig document als zoekobject opgeven. Ik denk dat er nog heel wat valt te perfectioneren aan deze zoekmachine, maar als je een sneak preview wilt van de toekomst van het zoeken, moet je Omnity zeker bekijken.
Wil je de wereld een beetje beter maken dan kun je gebruik maken van Goodsearch (https://www.goodsearch.com/) of Ecosia (https://www.ecosia.org/). Beide zoekmachines doneren een deel van de advertentie-inkomsten uit zoekacties aan goede doelen. Bij Goodsearch kun je zelfs je eigen goede doel benoemen. Hoe meer je zoekt, hoe meer je geeft.
Alltheinternet (https://www.alltheinternet.com/) heeft een uitgesproken ouderwetse uitstraling, maar het handige is dat je er kunt kiezen uit een stuk of 40 zoekmachines. Ook kun je je zoekactie laten uitvoeren door alle zoekmachines tegelijk. Het klinkt iets mooier dan het is, want de lijst bevat bijvoorbeeld ook de zoekmachine van Wallmart, maar er blijven genoeg mooie keuzes over.
Het Zwitserse etools.ch (https://www.etools.ch) benadert 16 zoekmachines tegelijk en laat bij ieder resultaat zien door welke machine het is gevonden.
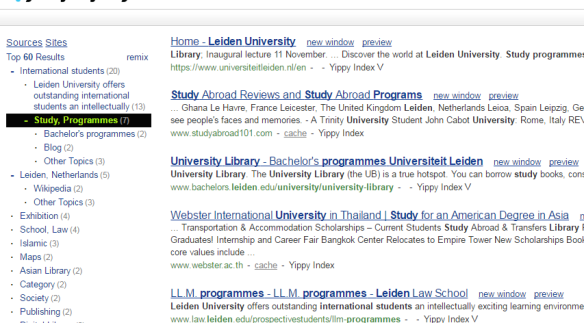
Yippy (https://www.yippy.com/) heeft een weinig serieus klinkende naam, het komt dan ook voort uit het al even koddig klinkende Clusty, maar het is wel een multisearch engine met een heel fijne feature: hij geeft bij de zoekresultaten ook een verdeling in rubrieken en toont de websites die de meeste resultaten bevatten.
SEO-slimmeriken zorgen ervoor dat ‘hun’ sites bovenaan de zoekresultaten verschijnen. Wil jij ze op jouw beurt weer te slim af zijn, gebruik dan Millionshort (https://millionshort.com). Je kunt deze search engine de opdracht geven om de bovenste zoekresultaten (van 100 tot een miljoen) laten verwijderen. Ik vraag me af of het precies werkt zoals wordt gesuggereerd, maar het levert in ieder geval verrassende resultaten op. Een mooie functie is bovendien dat je sites met advertenties kunt uitsluiten
En tenslotte een geweldig leuke semantische zoekmachine die mij persoonlijk veel voldoening heeft gebracht. Whatismymovie (https://whatismymovie.com/) geeft antwoord op vervelende vragen als ‘hoe heet die film ook alweer waarin die ene acteur (hoe heet hij toch?) de rol van evangelist speelt die in een andere film ooit de rol van Cyrano de Bergerac vertolkte?’ Type in ‘Cyrano’ en ‘preacher’ en je vindt het antwoord (Leap of faith). Zo mooi kan zoeken zijn.
F
 Het was een trip down memory lane, mijn bezoek aan de Internet Librarian International Conference 2016 in het Olympia Conference Center in Londen. In 1999 was ik in hetzelfde zalencomplex voor een bezoek aan de Online Conference. De enige aanpassing die het Olympia sindsdien aan de moderne tijd had gedaan was de tassencontrole, maar daar was het in Londen niet bepaald uniek in. Voor mijn werkgever moest ik destijds een verslag schrijven en ik weet nog dat ik de naam van die nieuwe zoekmachine nog even moest nazoeken in mijn aantekeningen. Oh ja, Google.
Het was een trip down memory lane, mijn bezoek aan de Internet Librarian International Conference 2016 in het Olympia Conference Center in Londen. In 1999 was ik in hetzelfde zalencomplex voor een bezoek aan de Online Conference. De enige aanpassing die het Olympia sindsdien aan de moderne tijd had gedaan was de tassencontrole, maar daar was het in Londen niet bepaald uniek in. Voor mijn werkgever moest ik destijds een verslag schrijven en ik weet nog dat ik de naam van die nieuwe zoekmachine nog even moest nazoeken in mijn aantekeningen. Oh ja, Google.
Tijdens de ILI was Google in een aantal presentaties prominent aanwezig, vaak in combinatie met meer moderne termen als Big Data en Artificial Intelligence. En waar Google toen werd geprezen als de toekomst van het zoeken, waren er nu meer kritische geluiden te horen. Is ons gebruikersprofiel van invloed op wat we voorgeschoteld krijgen? Is Google een Big Brother gevoed door Big Data? Moeten we een stel oncontroleerbare algoritmes laten bepalen welke zoekresultaten we te zien krijgen? Wie een tijdje geleden op “Top economist” zocht op Google, kreeg Trump als één van de eerste resultaten. Foutje in de algoritmes. Google geeft als je slokd of ende intikt automatisch de suggestie slokdarm en endeldarm, maar als je vagin of peni intikt, heeft het geen idee wat je bedoelt. Hoe fatsoensrakkerig mag een zoekmachine zijn? Als ik het Oudnederlandse woord bloken zoek, vind ik pas op de tweede pagina een resultaat, omdat Google voor mij bepaalt dat ik een tikfout heb gemaakt en alles over blokken wil weten. De onverholen weerzin die ik bij een aantal sprekers opmerkte over dit soort fouten/interpretaties/bedilzucht is eigenlijk best begrijpelijk. Informatieprofessionals willen dat onze klanten een resultaat krijgen dat klopt en dat een zoekmachine bij voorkeur alle resultaten geeft die exact beantwoorden aan de zoekopdracht.
Google indexeert vele miljarden webpagina’s en het aantal groeit nog steeds. Infoglut, het verschijnsel dat de hoeveelheid data zo groot wordt dat er steeds minder zinvolle informatie aan te onttrekken valt, is een reëel risico. Op dit niveau zijn recht-toe-recht-aan zoekmachines met exacte zoekresultaten geen optie meer. We moeten leren leven met slecht controleerbare machinale interpretaties en met zoekresultaten waarvan Google dénkt dat we ze willen zien. De grote zoekmachines zullen steeds meer gestuurd worden door kunstmatige intelligentie. Tegenspartelen heeft evenveel zin als protesteren tegen slecht weer. Maar er ligt natuurlijk een mooie taak voor de informatieprofessional om zijn klanten te wijzen op de beperkingen van Google, maar ook Bing, Yahoo, Yandex enz., en om ze kritisch te leren omgaan met de zoekresultaten.
En het is natuurlijk niet allemaal kommer en kwel. Het zit er dik in dat de tendens richting machine learning als prettig bijeffect zal hebben dat de behoefte aan zoekmachines voor beperkte dataverzamelingen (ik noem maar iets: bibliotheekcatalogi!) groeit. Old school zoekmachines die, als je zoekt op Trump, niet als resultaat “Top economist” geven en ook niet “Presidentskandidaat”, maar gewoon “Trump”, omdat dat is wat je zoekt. Is dat geen troostrijke gedachte?
Aan geboden een video recorder 2000 draaid wel is een video band bij verdere werking onbekend.misschien iets voor de verzamelaar.

Die advertentie op Marktplaats brak mijn hart, niet alleen vanwege de aandoenlijke variant van het Nederlands, maar vooral omdat dit in een notendop de teloorgang van een superieur stukje Nederlandse technologie demonstreert. Video2000 had meer kwaliteit dan VHS, maar toch werd dat laatste systeem de standaard. Videorecorders werden alleen nog gemaakt voor VHS-banden en Video2000 ging kansloos ten onder. Het is het principe van dominant design: na een rommelige beginperiode wordt één systeem , om wat voor reden ook, leidend en past de hele markt zich aan, ook als er betere alternatieven voorhanden zijn.
Dat verschijnsel zie je ook in het publicatieproces. Van oudsher worden artikelen gepubliceerd in tijdschriften omdat het nu eenmaal niet rendabel is om ze individueel te drukken en te verspreiden. In onze digitale tijd spelen die kosten nauwelijks een rol meer, maar toch blijft het tijdschrift, ook digitaal, een dominante publicatievorm. Raar eigenlijk. En dan heb ik het nog niet eens over de door het verleden bepaalde, maar al lang niet meer noodzakelijke dominantie van uitgevers in het digitale publicatieproces.
Dominant design is ook heel mooi te zien in het distributiemodel voor e-books. Van sommige leveranciers mag een universiteit een e-book maar uitlenen aan één persoon en slechts voor een beperkte periode, kortom dezelfde regels die je hanteert voor een papieren boek. Het verschil is dat een e-book een verzameling digitale nullen en eentjes is die je, letterlijk, voor hetzelfde geld onbeperkt aan de volledige wereldbevolking ter beschikking zou kunnen stellen. Natuurlijk begrijp ik wel dat er een verdienmodel moet zijn, maar niemand zou op deze specifieke formule zijn uitgekomen als hij al niet had bestaan voor het papieren boek. Het is alsof je een paard voor een auto spant omdat we dat vroeger nu eenmaal ook deden. Dominant design in optima forma.
Maar de meest schrijnende vorm van dominant design in ons vak bevindt zich aan de consumentenkant. Om een groot bereik te krijgen moest tekst tot heel recent worden gedrukt en verspreid. Omdat informatie dus relatief duur en schaars was, gingen we er terecht stilzwijgend van uit dat alles wat we tot ons kregen een zekere kwaliteit had, want je mag toch zeker verwachten dat je waar voor je geld krijgt! En dat impliciete vertrouwen is er nog steeds, getuige bijvoorbeeld de mevrouw die zeker wist dat de vluchtelingen onze banen krijgen omdat het op Facebook had gestaan. Een exces? Misschien, maar dat geldt niet voor al die mensen die klakkeloos het eerste het beste zoekresultaat van hun zoekmachine als waar accepteren zonder naar de bron te kijken (als Google zelf al niet als de bron wordt gezien). Die vorm van dominant design is kwalijker en waarschijnlijk hardnekkiger dan de voorbeelden die ik hierboven beschreef. En we zijn er nog lang niet van af.

Om te illustreren hoe slecht kinderen vaak toegerust zijn om internet te gebruiken vertelde Hanna Jochmann tijdens de Vogin IP-lezing op 3 maart in de OBA dat ze vaak hele vragen in Google invoeren. Even later spoorde de Amerikaanse zoekgoeroe Ran Hock ons juist aan om veel vaker dit soort vormen van natuurlijke taal te gebruiken bij zoekacties.
Huh?
Natuurlijk hebben ze alle twee op hun eigen manier gelijk. Jochmann toont hiermee aan dat kinderen Google niet zien als een zoekmachine, maar als een vraag-en-antwoordapparaat, waardoor ze geen optimale zoekopdrachten geven. En Ran Hock is enthousiast over de vooruitgang in Natural Language Programming (NLP), waardoor spreektaal steeds beter te interpreteren is door zoekmachines.
Hoe komt het dan dat er toch een vreemde tegenstelling in lijkt te zitten?
Het antwoord is simpel. Het stellen van vragen aan een Google duidt op onvermogen of een gebrek aan kennis van de mens (en echt niet alleen de schoolgaande mens) , terwijl de eigenschap om in spreektaal gestelde vragen te beantwoorden een kwaliteit is van de zoekmachine (en echt niet alleen Google). Als je er met een zonnige blik naar kijkt zou je kunnen zeggen dat het gebrek van de één wordt opgeheven door het vermogen van de ander. Maar is dat ook zo? Zonder mezelf als een Somberman te willen afschilderen, denk ik dat daar wel wat aan af te dingen valt.
Uit allerlei onderzoeken blijkt dat veel mensen geen onderscheid maken tussen feit en mening.’Als het op het internet staat zal het wel waar zijn.’ Peter Burger vertelde in zijn lezing dat journalisten zich vaak wel bewust zijn van het nut van factchecking, maar dat dat uiteindelijk veel te weinig gebeurt. Als de serieuze pers dat al niet doet, is het nauwelijks verwonderlijk dat ´gewone´ mensen blind varen op wat zij via internet tot zich nemen.
Er zit een niet eens zo subtiel verschil tussen de zoekopdracht
`Donald Trump´ AND Racist
en
`Is Donald Trump een racist?´
In het eerste geval is de opdracht ondubbelzinnig: geef resultaten met daarin ‘Donald Trump’ en Racist. Ik het tweede geval wordt minimaal de suggestie gewekt dat de zoekmachine met het (juiste) antwoord op de vraag komt en dan is het bovenste zoekresultaat bepalend, als we uitgaan van hoe mensen doorgaans hun zoekresultaten beoordelen.
Over dit soort zaken mag ik graag wat mijmeren, overigens zonder dat het mijn leven vergalt, en ik was dan ook geïntrigeerd door de titel van Ran Hocks verhaal: “Brave new search world”. Ik dacht dat hij daarmee verwees naar Aldous Huxley’s Brave New World, waarin hij een totalitaire, technologische samenleving beschrijft, een maatschappij die wordt geleid en gemanipuleerd door een kleine bovenklasse die de kennis beheert.

Met dat in het achterhoofd verwachte ik een verhaal van Hock over de nieuwste technologische inzichten met daarbij de nodige kanttekeningen. Maar van dat laatste was weinig te merken, waardoor het voor de Huxley-lezers leek of hij die wereld wel zag zitten. En ook het verhaal van de andere keynote speaker Pieter Cobelens, Generaal-Majoor B.D. en voormalig hoofd van de MIVD, ging in die richting. Zijn betoog ging over de noodzaak van hooggeschoolde informatieprofessionals die optimaal gebruik moeten maken van de nieuwste technieken (ik refereer nog maar even aan de kleine bovenklasse die de kennis beheert). En passant vertelde hij ons dat we rustig onze informatie op het internet kunnen achterlaten. Als je het maar versleutelt. En de overheid zorgt er wel voor dat er verder niets mee gebeurt.
Wat is dat toch met die door technologie, landsbelang of anderszins gedreven mensen die zo opgaan in hun fascinatie dat ze de doorsnee internetgebruiker, bewust of onbewust, veronachtzamen?
Het merendeel van de bezoekers aan de Vogin IP-lezing is verbonden aan een bibliotheek. Ze zijn er bij gebaat als hun klanten beschikken over de kritische vaardigheden om de informatie te vinden waar ze echt behoefte aan hebben. Voor het merendeel van de internetgebruikers is niet zoeken het probleem, maar vinden. Ik heb in de OBA allerlei interessante verhalen gehoord over de nieuwste technologische ontwikkelingen, over een veilig internet voor kinderen, professionele factchecking, social media tools en nog veel meer, maar het verhaal over hoe we er voor kunnen zorgen dat onze klanten kritische vinders worden heb ik ook hier weer gemist.
‘Zoeken en vinden’ was het thema van de Vogin IP-dag. Het zou mooi zijn als dat volgend jaar ‘Zoeken, vinden en er iets van vinden’ is. Oh ja, en over die ijsberen: als je zoekt op ‘Wist je dat ijsberen linkspotig zijn?’ vind je weliswaar een paar honderd hits, maar wie even kritisch verder zoekt , komt erachter dat dat pure onzin is.
(IGELU conference 2015 Budapest)

Nou, misschien zeggen niet álle biepers ja, en ik kan niet ontkennen dat ik met de titel van deze blog vooral gemakkelijk wil meeliften op het succes van de grote zomerhit, maar het is wél zo dat er bij de afgelopen IGELU conference nóg meer aandacht was voor Alma dan vorig jaar, zowel bij leverancier Ex Libris als bij de leden van de Ex Libris gebruikersgroep.
Dat ligt ook wel voor de hand als je kijkt naar de snelheid waarmee Alma wordt uitgerold. Op dit moment zijn er 230 bibliotheken die met Alma werken. Eind dit jaar zullen dat er 383 zijn (al moet daarbij opgemerkt worden dat ruim honderd van die nieuwe bibliotheken behoren tot een groot Noors consortium, maar toch). Ondertussen gaat de ontwikkeling van Alma gestaag door. Nog steeds wordt er iedere maand een update uitgebracht. Geleidelijk aan zal vanaf nu tot eind 2016 de interface worden vernieuwd. Een andere metamorfose, maar dan inhoudelijk, vindt plaats met de Community Zone. Die centrale database (nu nog te vergelijken met de Global Knowledge Base van SFX) bestaat vooral uit e-journals en e-books die tot nu toe vooral door Ex Libris werden toegevoegd, maar in de toekomst zullen de mogelijkheden om zelf records toe te voegen en te muteren geleidelijk worden uitgebreid, waardoor de Community Zone een soort WorldCat light kan gaan worden. Een opmerkelijke ontwikkeling.
Ook in de planning voor 2016: Benchmark Analytics. Het wordt bijvoorbeeld mogelijk om te zien hoe de snelheid waarmee een reservering wordt gehonoreerd binnen je eigen instelling zich verhoudt tot die bij de gemiddelde (Alma)bibliotheek. Ex Libris gaat ook werk maken van de opslag en het beheer van digitaal materiaal (DAM-functionaliteit). Voor de objecten die Leiden beheert, is de functionaliteit vooralsnog te beperkt. Het meest opmerkelijke in die ontwikkeling is dat er gebruik gemaakt wordt van cloudopslag bij Amazon. Ook bij het onderdeel acquisitie kwam Amazon ter sprake. Vanaf eind dit jaar wordt het mogelijk om volledig geïntegreerd binnen Alma te bestellen bij het internetwarenhuis. Integratie was toch al een veelgebruikt begrip als het ging om acquisitie. Het selectieproces wordt steeds meer binnen Alma getrokken. Nadat YBP als eerste grote leverancier aansloot op de real-time acquisition api van Alma zullen ook Coutts, EBSCO en andere leveranciers in de nabije toekomst aanhaken.

Zinsbegoocheling en beroepsverdwazing, of zag ik dit zakje snoep écht in het schap van een avondwinkel?
Dat zijn maar een paar van de krenten uit de ontwikkelpap die Ex Libris ons voorschotelde. Maar IGELU is een gebruikersorganisatie en daarom waren er met name presentaties voor en door gebruikers. Bij de Leidse afvaardiging (Hiltje, Derk-Jan, Bas en ondergetekende) was er uiteraard veel aandacht voor de ervaringen met Alma-migraties. Het was vooral goed om te merken dat Ex Libris inmiddels blijkbaar voldoende ervaring met dit traject heeft opgedaan om het redelijk gesmeerd te laten verlopen. Gebruikerstips die steeds weer terugkomen:

Oh, oh, Budapest, mooie stad achter de duinen.
Opvallend was verder dat twee universiteiten (Manchester en Sheffield) de overgang naar Alma hebben gebruikt om af te stappen van het boetesysteem. Hun oplossing is een langlopende uitleentermijn, met als voorwaarde dat de lener het werk terug moet brengen als het door een ander is aangevraagd. Beide universiteiten ervaren de aanpassing als positief. Minder rompslomp en grotere gebruikerstevredenheid zijn de belangrijke voordelen.
|
Ander nieuws:
|
Was het dan alleen maar rozengeur en maneschijn daar in Budapest (en dan doel ik uiteraard niet op de schrijnende toestanden op het station, een paar kilometer van de conferentielocatie)? Nee, zeker niet. Werken in de Cloud en met SaaS (Software as a Service) heeft ook zo zijn nadelen. Doordat alle bibliotheken eigenlijk op één Alma zitten, zijn er minder mogelijkheden om het systeem naar eigen smaak in te richten. Zo werd er geklaagd over de de api’s. Dit zijn kleine programmaatjes, vaak gemaakt door gebruikers, waarmee geautomatiseerd allerlei acties in Alma kunnen worden uitgevoerd. Er zijn er inmiddels al meer dan honderd, maar het succes van de api’s heeft als nadeel dat ze het systeem zwaar belasten en daarom heeft Ex Libris een maximum aantal api-acties per bibliotheek ingesteld. Een aantal bibliotheken was verbolgen over deze eenzijdig genomen maatregel. Ook werd er gemopperd dat er geen vrijheid is om velden te indexeren, waardoor het bijvoorbeeld lastiger kan zijn om in Alma batchmatig gegevens te wijzigen. De (wat omslachtige) oplossing is nu om de data te exporteren, aan te passen en daarna weer te importeren.
Maar dat neemt niet weg dat over de gehele linie de bibliotheken, ook de mopperende, een positieve waardering hebben voor het implementatietraject en het werken met Alma. Een geruststellende gedachte.

Mijn vakantie is net achter de rug. Het is nog rustig op de UB. Een goed moment om even achterover te zitten en met geloken ogen te mijmeren over ‘het vak’. Ik ben zelf nog van de generatie die later aan zijn kleinkinderen vertelt over de tijd dat opa nog artikelen opzocht in een grote kast die ‘kaartenbak’ werd genoemd. Toen ik in 1999 begon als bibliotheekautomatiseerder hadden we een OPC, een paar databases en een heus torentje met cd-roms. In sneltreinvaart nam het aantal e-journals en databases toe, we kregen Metalib om het zoeken in de brij aan bronnen enigszins overzichtelijk te maken en inmiddels hebben we alweer een paar jaar de beschikking over Primo, waarmee onze gebruikers via één vakje ons gehele aanbod kunnen doorzoeken. Het is nog niet perfect, maar het komt in de buurt, toch? Of niet helemaal?
Een greep uit een aantal artikelen over zoekgedrag van studenten:
‘Our observations verified the findings of others, such as the lack of understanding of constructing search queries and employing advanced searching techniques’ [1].
‘ We identified… the lack of an overall understanding of the interrelationship among the library catalog, databases, the discovery tool , and scholarly publications.’[2]
‘We found that students had limited attention spans when confronted with myriad results.’[3]
‘Even though many of the students had had a course-integrated library instruction session before participating in the study, it did not seem to increase their evaluative skills’[4] .
‘Students in this study seemed to have little conceptual understanding of how information is structured and how searches work in either Google or the federated search tool (and by extension, all search tools), yet they all ranked themselves highly in terms of their own research skills. [5]
Wie zelf verder zoekt zal genoeg voorbeelden vinden van onderzoeken waaruit blijkt dat studenten (maar echt niet alleen studenten) bij hun zoekacties nauwelijks gebruik maken van quotes, weinig Booleaanse operatoren gebruiken, alleen naar de eerste paar zoekresultaten kijken, kortom, waaruit blijkt dat de functionaliteit van onze prachtige zoeksystemen maar voor een klein deel wordt benut. Toen ik een aantal jaren geleden zelf een onderzoekje deed naar zoekgedrag, zei een student het onomwonden: ‘ik wil gewoon Google’. Inmiddels zijn we zo ver dat we iets bieden dat aardig in de buurt komt, maar daarmee hebben we ook een Google-achtige manier van vinden binnengehaald: door de grote massa aan gegevens vind je altijd wel wat, maar de kans op een (gedeeltelijke) mismatch is groot, mede door het slordig gebruik van zoektermen, het ontbreken van kritisch vermogen als het gaat om het beoordelen van de bronnen en de onwil om verder dan de eerste paar zoekresultaten te kijken, om maar eens wat te noemen. Slordig zoeken is niet zo’n ramp als je op zoek bent naar een camping in Bretagne, maar voor wie zoekt naar wetenschappelijke informatie is het niet verstandig om het eerstgevonden strootje in een hooiberg als speld te behandelen. En voor alle duidelijkheid: ik doe niet aan Google-bashing, want net als Primo biedt Google allerlei mogelijkheden om precieze zoekacties uit te voeren. Alleen wordt daar maar mondjesmaat gebruik van gemaakt.

En dan is de grote vraag natuurlijk: hoe zorgen we ervoor dat er betere resultaten worden gevonden? Instructie is natuurlijk belangrijk, en daar doen we ook veel aan, maar in de waan van de dag zijn veel zoekers geneigd om vooral aan het eindresultaat te denken en niet aan de weg daarnaartoe[6]. Misschien moeten we sommige geavanceerde zoekfuncties (zoeken op titel etc.) meer prominent aanbieden. Of misschien kunnen we de zoekvraag koppelen aan achtergrondinformatie die we hebben van de student. Welke studie volgt hij? In welk jaar zit hij? Als hij zoekt op ‘Parma’ en we weten dat hij geschiedenis studeert, hoeven we een boek over de economie van de stad Parma niet prominent aan te bieden en werken over de hertog van Parma wél. Maar is dat niet te bevoogdend? Houden we hem zo niet dom? Of moeten we er op gokken dat de ontwikkeling van de semantisch technologie ons naar een zorgeloos zoekwalhalla zal brengen? En zo buitelen de vragen over elkaar.
Ik open mijn ogen en realiseer me dat ik nog een paar mailtjes moet beantwoorden. Als iedereen weer terug is van vakantie gaan we dat zoeken eens goed aanpakken. Toch?
[1] Heather A. Dalal, Amy K. Kimura, Melissa A. Hoffman, “Searching in the wild: Observing Information-Seeking Behavior in a Discovery Tool”, Association of College & Research Libraries Proceedings, (2015): 668
[2] Ibid., 669
[3] Beth S. Bloom, Marta Deyrup, “The truth is out: how students REALLY search”, Proceedings of the Charleston Library Conference, (2012): 204
[4] Lea Currie, Frances Devlin, Judith Emde and Kathryn Graves, “Undergraduate search strategies and evaluation criteria”, New Library World, Volume 111, Number 3/4, (2010): 113
[5] Helen Georgas, “Google vs. the library (part II): student search patterns and behaviors when using Google and a Federated Search Tool”, Libraries and the Academy, Volume 14, Number 4 (2014): 527
[6] Melissa Gross and Don Latham, “Undergraduate Perceptions of Information Literacy: Defining, Attaining, and Self –Assessing Skills”, College & Research Libraries, Volume70, Number 4(2009): 345

Het is zeker niet de belangrijkste vraag in bibliotheekland, maar wel al jaren de meest gestelde: is het nu dé GGC of hét GGC? GGC staat voor Gemeenschappelijk Geautomatiseerd Catalogiseersysteem en dus is ‘het’ correct, maar bij afkortingen wil de onzijdigheid nog wel eens verdwijnen. Datzelfde geldt voor de de/het-vraag, want in een paar stappen zullen we afscheid nemen van het GGC (laat ik het daar maar op houden). De UKB-bibliotheken stappen over op WorldShare (zonder lidwoord), ook van OCLC. WorldShare is, heel kort door de bocht, een internationale GGC. Overgang naar WorldShare betekent dat we aansluiten bij internationale standaarden en regels, dat we beter gebruik kunnen maken van metadata die door leveranciers wordt geleverd en dat we efficiënter kunnen werken. Bovendien is de verwerking van papier en elektronisch materiaal in WorldShare beter geïntegreerd dan in het GGC.
Voor de oppervlakkige beschouwer lijkt de overgang naar WorldShare misschien een fluitje van een cent. Onze gegevens zitten er immers al in. Maar zoals meestal in het leven is de werkelijkheid net iets genuanceerder. In de loop der jaren is het grootste deel van het Leidse bezit inderdaad overgezet naar WorldCat, maar de kwaliteit van de conversie was aanvankelijk nog niet optimaal en daarom moet er nog wel wat herstelwerkzaamheden verricht worden. Bovendien staan de exemplaargegevens nog niet in WorldCat. Die slag moet nog gemaakt.
Maar de overgang brengt meer wijzigingen met zich mee. Zo zullen we afscheid nemen van WinIBW. Hiervoor in de plaats komt de gloednieuwe editor Record Manager. Het Picaformaat wordt ingeruild voor het internationaal veel meer ingeburgerde Marc21. Ook het IBL-systeem zal op termijn vervangen worden door een WorldShare-variant. Omdat dit nieuwe systeem voorlopig nog even op zich laat wachten, zal ook na de overgang naar WorldShare het GGC nog in gebruik blijven om de interbibliothecaire verkeer in stand te houden.

OCLC biedt een totaaloplossing met naast WorldCat onder meer een backendsysteem, maar de overgang naar WorldCat betekent niet dat we automatisch ook de andere producten gaan afnemen. Over de toekomst van onze linkresolver (nu is dat SFX) is bijvoorbeeld nog geen beslissing genomen.
De grote vraag is nu natuurlijk wanneer de overgang naar WorldCat gaat plaatsvinden. UKB en OCLC werken samen in een landelijk project. De universiteiten zullen één voor één, of hooguit in groepjes van 2 of 3 overgaan. De TU Delft bijt het spits af. Volgens de huidige planning zullen zij in juli gaan catalogiseren in WorldShare. Leiden zal zoals het er nu naar uitziet in de zomer van 2016 overgaan. We hopen tegen die tijd meer duidelijkheid te hebben over ons backendsysteem. Blijft het Aleph? Wordt het de opvolger Alma? Of wordt het toch WMS? Omdat WorldShare en het backendsysteem voor een groot deel gebruik maken van dezelfde gegevens zijn dat belangrijke vragen. Bovendien staat ons begin 2016 een grote verhuizing van collecties te wachten. Het is beter om zo’n grote operatie te doen in een systeem waarin we helemaal thuis zijn. En natuurlijk betekent het achteraan aansluiten ook dat we minder geconfronteerd worden met kinderziektes (want die zijn er nu eenmaal altijd). Dat betekent overigens niet dat we tot die tijd achterover leunen. We kunnen nu al veel doen om ervoor te zorgen dat we straks geolied en zonder onnodig verlies aan kwaliteit de stap kunnen maken. Er is daarom nu al een projectgroep in het leven geroepen.
Maar we hoeven we niet tot de zomer van 2016 te wachten op nieuwe OCLC-producten, want eind dit jaar zal de vervanger van Picarta, WorldCat Discovery, in gebruik worden genomen. Overigens betekent dat niet we daarmee direct afscheid nemen van Picarta: dat blijft nog tot een niet nader genoemde datum beschikbaar.
{kind=link}