Als pdf (beter leesbaar)


Verschenen in Informatieprofessional 04/2017 (Informatieprofessional.nl)

Ach, dat waren nog eens mooie tijden. De onwetende student ging naar de informatiespecialist en die kon precies vertellen hoe en waar de gevraagde informatie te vinden was. Over de kwaliteit hoefde niemand zich zorgen te maken: Bij de poort van de bibliotheek zat immers een vakreferent die er voor zorgde dat alle niet wetenschappelijk verantwoorde literatuur geweerd werd. Tegenwoordig is dat wel anders. In de (om het afgrijselijke woord maar weer eens te gebruiken) tsunami aan informatie die we over ons heen krijgen moeten de bibliotheken hun uiterste best doen om een overzicht te houden op wat zich waar bevindt.
En dan zitten we ook nog in het tijdperk van het fake news. De wetenschappelijke wereld heeft te maken met het groeiende ongemak van de predatory publishers, uitgevers die het Open Access-model misbruiken door auteurs te lokken met snelle en vrijwel gegarandeerde plaatsing van hun artikelen in goed aangeschreven, peer reviewed journals en dat tegen lage publicatiekosten. Wie zijn Van Kooten en De Bie kent denkt direct aan neutronenkorrels, en inderdaad, vaak blijkt er nauwelijks of geen peer review te zijn, blijven ook de taalfouten gewoon staan en is het e-journal niet meer dan een slordig vormgegeven website, die vaak dan ook niet is geïndexeerd door degelijke databases als Thompson Reuters en EBSCO. Ondanks die geur van onbetrouwbaarheid zijn er genoeg auteurs die hun artikelen onderbrengen bij zo’n malafide uitgever. Gebrek aan geld en een grote publicatiedruk vergroten maar al te vaak de aantrekkingskracht en vertroebelen de kritische blik van de (vaak nog jonge) wetenschapper.
De afgelopen jaren is het aantal predatory publishers enorm gegroeid. De Amerikaanse bibliothecaris Jeffrey Beall begon in 2011 met een lijst waarop 18 potential, possible, or probable predatory publishers stonden. Toen Beall zijn lijst begin dit jaar onverwacht offline zette, stonden er bijna 1300 roofdieruitgevers op. Natuurlijk staan er genoeg goede artikelen in de journals die door predatory publishers worden uitgegeven worden, maar de rammelende acceptatiecriteria zorgen er voor dat er ook veel kaf tussen het koren zit, en dat is een kwalijke zaak (denk bijvoorbeeld aan artikelen in medische tijdschriften).
Het is lastig om dat kaf van het koren te scheiden. Vorig jaar heeft DOAJ (Directory of Open Access Journals, de meest bekende aanbieder van OA journals) veel tijdschriften verwijderd en werden de toelatingscriteria aanmerkelijk verscherpt. Niettemin bevat de DOAJ nog honderden journals die voorkomen in Beall’s lijst. Wat is waarheid? Wie heeft gelijk?
Het betekent in ieder geval dat de mensen aan de poort van onze informatiecentra een scherp oog moeten hebben voor deze (al dan niet) wetenschappelijke gelukszoekers. Er circuleren op internet al veel pagina’s waarop tips staan om predatory journals te kunnen identificeren. Het gaat dan om vragen als ‘Heeft het tijdschrift een formele editorial board?’ of ‘Is het copyright goed en duidelijk geregeld?’ Uitgebreide voorbeelden zijn ondermeer te vinden bij WAME (met de criteria van Beall, DOAJ), the MAP Newsletter en Think,Check,Submit (met daarachter o.a. PubMed Central en Springer.)
Het is goed om de werkelijk onbetrouwbare tijdschriften buiten de deur te houden, want eenmaal binnen worden ze door onze klanten, die vertrouwen in ons hebben, als betrouwbaar beschouwd en dus is Minder! Minder! Minder! in dit geval nu eens volkomen op zijn plaats.

Regionaal Historisch Centrum Limburg in Maastricht, gevestigd in de oude Minderbroederskerk
Op 2 en 3 februari vond in het Regionaal Historisch Centrum Limburg in Maastricht de internationale conferentie Parchment, Paper and Pixels. Medieval Writing and Modern Technology plaats. De bijeenkomst werd georganiseerd door SSNM (Schrift en Schriftdragers in de Nederlanden in de Middeleeuwen), het Huygens Instituut voor Nederlandse Geschiedenis, het RHCL en het Henri Pirenne Instituut voor Middeleeuwse Studies te Gent. Hoewel de titel doet vermoeden dat de presentaties alleen paleografie en oorkondeleer als onderwerp hadden, was de scope breder dan dat. Het doel van de conferentie was om de relatie tussen de Middeleeuwse en digitale wetenschappen in het algemeen te analyseren. Mediëvisten die op geen enkele manier gebruik maken van digitale hulpmiddelen zullen dun zijn gezaaid, alleen al de aanwezigheid van gedigitaliseerd handschriftelijk materiaal op het web heeft het onderzoek de laatste decennia veel toegankelijker gemaakt. Maar voor Digital Humanities onderzoek is wel wat meer nodig. Tijdens het symposium werd een aantal succesvolle projecten gepresenteerd.
Opgeleid als Mediaevist ben ik uiteraard breed geïnteresseerd in de ontwikkelingen in mijn vakgebied. Maar vanuit mijn functie bij de UBL was het ook boeiend om te zien van welk type tools onderzoekers op dit moment gebruik maken bij hun onderzoek, welke behoeften spelen, en bij welke onderdelen van het onderzoeksproces de bibliotheek een rol kan spelen.
De keynote op de eerste dag werd verzorgd door Peter Stokes. Hij is de bedenker van DigiPal, een open source tool voor het vergelijken van schrift. De software stelt onderzoekers in staat om te zoeken naar lettervormen, en de karakteristieke kenmerken eenvoudig met elkaar te vergelijken. Je kunt bijvoorbeeld letters over elkaar schuiven, en ze op een tijdlijn zetten. Hoewel Stokes DigiPal oorspronkelijk ontwikkelde voor Engels elfde-eeuws schrift, wordt de software inmiddels breder toegepast, met als resultaat SephardiPal (Hebreeuws schrift van het iberisch schiereiland), ScandiPal (het schrift van Scandavische fragmenten) en BayeuxPal (lettervormen op het tapijt van Bayeux).
In het verleden werd er nog wel eens getwijfeld aan de status van paleografie en codicologie: was het niet eigenlijk een hulpwetenschap voor historici? De DigiPal tool maakt het werk van de onderzoeker makkelijker, maar neemt het niet uit handen. DigiPal vertelt je niet of handschrift A en B door dezelfde kopiist zijn geschreven of niet, de interpretatie moet nog altijd van de onderzoeker zelf komen. Toch bestaat de angst dat tools als DigiPal er op den duur voor zorgen dat de rol van de paleograaf helemaal verdwijnt, en op basis van kwantitatieve analyses ook de conclusies kunnen worden getrokken. Dit was precies het onderwerp van de paper van Mats Dahllöf, die zich bezighoudt met automatische toeschrijving. In zijn abstract claimt hij een nauwkeurigheid van 97,1 % te bereiken, maar helaas moest hij door ziekte afzeggen. Natuurlijk wordt pas door de juiste vragen, methode en analyses van de onderzoeker software een echte onderzoekstool. Tegelijk vereist het andere kwaliteiten van de onderzoeker. Is het ook nodig dat zij zich al deze nieuwe technieken eigen maken? Tot op welke hoogte? En hoe komen ze aan deze kennis?
Miriam Edlich-Muth houdt zich bezig met de verspreiding van Floris ende Blancefloer. Van deze tekst zijn vele versies en vertalingen gemaakt, en het verhaal is dan ook van Griekenland tot en met IJsland bekend. Zoals veel onderzoekers begon zij met het vastleggen van kwantitatieve gegevens in een spreadsheet, maar al snel realiseerde ze zich dat deze methode niet voldeed aan haar wensen. Met behulp van een ontwikkelaar op haar afdeling maakte ze enkele zogenaamde heatmaps en dendrogrammen (voor het maken van een hiërarchische cluster analyse), tools die veel worden gebruikt door statistici. Uit diverse papers bleek dat onderzoekers op verschillende niveaus hulp kunnen gebruiken bij Digital Humanities onderzoek. In de eerste plaats bij het kiezen van de juiste tool. Hiltmann & Gniffke wilden bijvoorbeeld TEI gebruiken om de ontwikkeling van de Franse tekst “Comment les obseques se doivent faire”, over de uitvaart van edelen, in kaart te brengen. Als snel kwamen ze erachter dat de standaard hiervoor voldeed. TEI is een xml standaard bedoeld voor het maken van digitale edities en te plat voor het visualiseren van relaties tussen teksten. Ook wilden ze allerlei zaken in de standaard stoppen die er eigenlijk helemaal niet in thuis horen, en waar waarschijnlijk veel betere tools beschikbaar voor zijn. Precies hierin kan een Centre for Digital Scholarship een belangrijke rol spelen. Hier beschikt men over een overzicht van de beschikbare tools en technieken in de diverse vakgebieden en de toepassingen tot dat moment. Software die binnen het ene vakgebied is ontwikkeld om taken te automatiseren, kan in het andere vakgebied geschikt zijn om nieuwe onderzoeksvragen te beantwoorden. Ook kan een dergelijk loket een rol spelen bij het samenbrengen van onderzoekers uit verschillende disciplines. Het onderzoek van Stephen Smith en Deborah Thorpe liet zien waar een dergelijke samenwerking toe kan leiden. Smith houdt zich bezig met de ontwikkeling van medische hulpmiddelen voor patiënten met neurologische aandoeningen, en Thorpe is paleograaf. Samen onderzochten zij neurologische aandoeningen in de middeleeuwen aan de hand van (handgeschreven) teksten. Een bekend voorbeeld hiervan zijn de teksten van de 13de eeuwse Tremulous hand of Worcester, herkenbaar aan zijn bevende schrift. Opvallend is dat veel kopiisten, waaronder de Tremulous hand, ondanks hun conditie nog heel lang door konden schrijven. De onderzoekers wilden achterhalen aan welke aandoening zij leden. Was het mogelijk de ziekte van Parkinson, of toch Alzheimer?

Ook het magische woord IIIF kwam een aantal keer voorbij. Verschillende onderzoekers lieten weten dat ze staan te springen om de mogelijkheden van het protocol te gaan gebruiken. Ze willen bijvoorbeeld gedigitaliseerde handschriften over een specifiek onderwerp op één plek samenbrengen om ze beter te kunnen vergelijken, of gedigitaliseerde handschriften transcriberen en annoteren, zoals wordt gedaan in French Renaissance Paleography.
Agata Dierick vertelde over Itinera Nova, een voorbeeld van een succesvol crowdsourcings-project geïnitieerd door het stadsarchief van Leuven. Doel is het digitaliseren en ontsluiten van de registers van de Leuvsense schepenbank (1362-1795). Aangezien het bijna een half miljoen folia betreft, heeft men hiervoor de hulp van vrijwilligers ingeroepen. Hiervoor werd een online platform ingericht met handleidingen, filmpjes en mogelijkheden voor kennisuitwisseling. Ook werd een interactieve online tutorial paleografie ontwikkeld.
De keynote op de tweede dag werd gegeven door Georg Vogeler van de universiteit van Graz. Hij werkt hier als Digital Humanities specialist voor het ‘Zentrum für Informationsmodellierung in den Geisteswissenschaften’. Hij vertelde met name over de uitdagingen bij het integreren van twee charter databases: Regesta imperii en Monasterium.net. Regesta imperii heeft een tijd geleden de ruwe data vrij beschikbaar gesteld onder CC-BY licentie. Hierdoor was het mogelijk geworden om de dataset te integreren in Monasterium.net, een database platform dat zelf ook weer verschillende typen bronnen samenbrengt: gedigitaliseerde gedrukte edities, beschrijvingen en scans van charters en aanvullende data die alleen via de website beschikbaar wordt gesteld. Integratie levert niet alleen een betere vindbaarheid op, maar ook een verbetering van de functionaliteiten. Wat is hiervoor nodig?
Allemaal zaken waar in Nederland dankzij de activiteiten van het NDE gelukkig al hard aan wordt gewerkt.
In zijn slotbeschouwing stelde Georg Vogeler vast dat onderzoek aan de ene kant steeds vaker interdisciplinair is, maar dat dit aan de andere kant ook weer eigen specialisaties aan het worden zijn. “ Hij vraagt zich dan ook af: are we narrowing down again?” Samenwerking en kennisdeling is noodzakelijk voor innovatie, dus de vraag is hoe dit kan worden voorkomen. Ook hierin kan volgens mij de bibliotheek (en met name een CDS) een rol spelen, doordat de kennis over tools en methodes hier niet alleen wordt verzameld en gedocumenteerd, maar ook weer wordt gedeeld. Dat kan door lezingen, conferenties en workshops, maar ook met een-op-een contact met onderzoekers. De bibliotheek kan op deze manier ook fungeren als motor voor innovatie.
Saskia
p.s. De tremulous hand bleek trouwens aan een essentiële tremor te lijden, d.w.z. zonder aanwijsbare oorzaak. Dat op sommige pagina’s het schrift een stuk minder bibberig is, komt volgens de onderzoekers doordat de kopiist ofwel heeft uitgerust, ofwel licht beschonken was. Een borrel was in de middeleeuwen dus niet alleen een beloning na het schrijven…
Als pdf (beter leesbaar).



Dit artikel verscheen in InformatieProfessional 2017/1 (informatieprofessional.nl)
 Begin september 2016 was ik bij het TPDL 2016 in Hannover. Het TPDL is een conferentie betreffende de theorie en praktijk van Digitale bibliotheken. Deze conferentie was tot 2011 bekend onder de naam ECDL (nee, niet het European Computer Driving Licence, maar dat was wel de reden van de naamswijziging) en wordt al bijna 20 jaar gehouden.
Begin september 2016 was ik bij het TPDL 2016 in Hannover. Het TPDL is een conferentie betreffende de theorie en praktijk van Digitale bibliotheken. Deze conferentie was tot 2011 bekend onder de naam ECDL (nee, niet het European Computer Driving Licence, maar dat was wel de reden van de naamswijziging) en wordt al bijna 20 jaar gehouden. 
De eerste keynote was door David Bainbridge (University of Waikato, Hamilton, New Zealand) met als titel “Mozart’s laptop”, wat mij intrigeerde. Op zich was het onderwerp interessant, namelijk over muziek in de Digitale Library, maar het ging eigenlijk niet over Mozart’s laptop. Ik had verwacht te horen hoe Mozart gebruik zou maken van een laptop als die beschikbaar was in zijn tijd. In plaats daarvan ging het over een systeem (Expediteee) waarin men op een gelijksoortige manier tekst, plaatjes, vector graphics en muziek kon opgeslaan en samenvoegen. Grappig was dat in muziek gezocht kon worden door “query by humming”. Hier werd gebruik gemaakt van audio finger printing. Ook werd Online Dynamic Time Warping (OTW) getoond. Dit is een techniek waarbij de computer de muziek kan volgen die van bijv. een iPad gespeeld wordt. Hiervoor is een soort OCR voor muziekschrift nodig zodat de computer de noten kan lezen en interpreteren, de gespeelde muziek moet geanalyseerd worden en hieruit wordt bepaald welk stuk van de muziek op dat moment wordt gespeeld. Zo kan de computer de bladmuziek op het juiste moment “omslaan”, zodat de musicus dat niet hoeft te doen.
Ook werd er een manier getoond om muziekvideo’s uit te breiden met extra lagen, zoals lyrics, scores, trivia en gitaarakkoorden. Deze lagen konden dan getoond worden terwijl de muziekvideo speelt.
Er was een presentatie waarin het volgende doel werd gesteld: spotify the sciences. Door het delen van verhalen kan meer onderzoek gedaan worden, dus deel de kennis met de wereld. Dat was the bereiken door bibliotheken, archieven en musea te verbinden, data delen makkelijk te maken, primaire data persistent beschikbaar te maken, een corpus moet clickable zijn (eenvoudig downloaden/gebruiken van hele selectie) en collaborative research moet beter ondersteund worden. Allemaal zaken waar iedereen het vast over eens is, maar wat toch lastig te bereiken zijn.
Er was een heel gepassioneerde presentatie van Annika Hinze: The challenge of creating geo-location markup for digital books. Leuk om naar te luisteren omdat de presentatrice duidelijk er heel enthousiast over was. Het ging over Literacy tourism (het boek lezen op de plaats waar het over gaat) en vooral over de problemen die overkomen moeten worden om de data te verkrijgen: welke soort kaart gebruik je? Het detailniveau is niet altijd hetzelfde namelijk en moet passen bij het boek. De hiërarchie in het verhaal is ook belangrijk. Soms gaat het hele verhaal over een bepaalde plek (bijv. een tuin), dit kan je dan aangeven als een gateway. Daarna gaat het verhaal over specifieke plekken binnen die plek (De Chinese tuinen), die je aangeeft als area. Ook kan er beschreven worden hoe je van een plek naar een andere plek loopt (bijv. van de Chinese tuinen naar de waterval), dit wordt aangegeven met een path. Tenslotte kan een specifieke plek worden beschreven (bijv. onder de waterval), dit is dan een point. 
Om dit allemaal goed te kunnen doen moet de markup met de hand gedaan worden. Als een specifieke plek in het verhaal genoemd wordt, gaat vaak de tekst hierna ook nog over die plek of houdt daar verband mee. Omdat het handwerk is, moeten duidelijke instructies worden gegeven aan de personen die het uitvoeren om zoveel mogelijk consistente resultaten te krijgen.
Soms is het gewoon niet duidelijk om welke locatie het gaat (te globaal aangeduid), soms is de locatie niet te vinden, soms wordt er alleen maar gepraat of gedacht over een locatie, en soms zijn het fictionele locaties (platform 9 3/4 uit Harry Potter). De beslissingen die genomen worden hierover tijdens het maken van de markup, moeten dan ook onderbouwd opgeslagen worden.
David Wilcox van DuraSpace hield een workshop over Fedora 4, wat interessant voor ons is aangezien we Fedora 3 gebruiken in onze nieuwe repository infrastructuur en de overstap naar Fedora 4 een kwestie van tijd is. Fedora staat voor Flexible Extensible Durable Object Repository Architecture en is zoals gezegd de basis van onze repository infrastructuur. Het verschil tussen Fedora 3 en 4 is dat de laatste nog meer gebruik maakt van open standaarden, het alles opslaan als een web resource waarvan alle “eigenschappen” (properties zoals metadata) opgeslagen zijn als RDF triples. Hierdoor is Fedora 4 Linked Data Platform compatible. Hiernaast gebruiken ze open standaarden zoals Memento (voor versioning) en WebAccessControl (voor authorization, XACML wordt nog wel ondersteund).
Interessant is dat Fedora 4 echt terug naar de basis gaat; het gaat vooral om het duurzaam bewaren van de objecten en gerelateerde metadata en het heeft een API om objecten en metadata toe te voegen, lezen, wijzigen en verwijderen (CRUD), inclusief transactions en versioning. Alle andere zaken (zoals zoeken en afbeelden van objecten) worden uitbesteed aan andere componenten. Dit lijkt in eerste instantie nogal een mager systeem op te leveren wat eigenlijk niet veel kan. Maar op zich is die focus goed, want wat het wel doet, doet het als de beste. Andere componenten kunnen op een standaard manier gekoppeld worden aan Fedora 4. Ten eerste via de API. Ten tweede wordt bij elke gebeurtenis (event) binnen Fedora 4 een bericht uitgezonden, waarbij ze gebruik maken van de JMS standaard. Hier kunnen andere componenten naar luisteren en actie ondernemen als er een gebeurtenis is die hen interesseert. Ook kan bijvoorbeeld Apache Camel gebruikt worden om te luisteren naar de berichten, waarbij deze SOLR aanstuurt om de indexen bij te werken. Op deze manier is er een krachtige samenwerking mogelijk tussen componenten waarbij elk component doet waarin ie het beste is.
Zowel met Islandora en Hydra wordt nauw samengewerkt zodat deze componenten goed passen binnen Fedora 4.
In de pauze heb ik even met David Wilcox gepraat over Islandora en met name de CLAW. De CLAW is het project om de volgende generatie van Islandora te maken, die samen kan werken met Fedora 4 en Drupal 8. Hij wist niet precies wanneer de CLAW klaar zou zijn, maar wist wel te vertellen dat er een script zou zijn om makkelijk over te gaan naar de nieuwe versie en dat er gewerkt werd om dit nog makkelijker te maken.
Hierna hebben we nog gekeken naar de REST API die Fedora 4 gebruikt. Hier kan je ook zelf mee spelen op https://demo.fcrepo.org:8080/fcrepo/rest. Bedenk wel dat dit een test systeem is dat elke nacht opgeschoond wordt. Met behulp van SPARQL update kunnen de RDF triples gewijzigd worden. Voor meer informatie zie introducing-fedora-4 en hands-on-with-fedora-4.
Hieronder nog enkele andere presentaties en workshops die ik nog kort wil noemen omdat ze apart, leuk of interessant waren.
Ten eerste was er een presentatie over een manier om muziek bij een video te suggereren door iemand van de TU Delft: From Water Music to ‘Underwater Music’: Multimedia Soundtrack Retrieval with Social Mass Media Resources (Cynthia C. S. Liem). Het bleek dat het bij een video vooral om het verhaal gaat en minder om het beeld bij de keuze van de muziek. Ze maakte gebruik van IMdb om een soortgelijke film te vinden en daarin stond dan een referentie naar de film muziek die via last.fm werd gevonden.
Een workshop over text mining was ook interessant: Text mining workflows for indexing archives with automatically extracted semantic metadata (Riza Batista-Navarro). Hierbij ging het over een manier om text mining te gebruiken om beter te kunnen zoeken. Als full-text search wordt toegepast kunnen sommige woorden een dubbele betekenis hebben (zoals bank voor geldzaken of om op te zitten) en dingen hebben vaak meerdere woorden die naar hetzelfde ding verwijzen (zoals bank en sofa). Hierdoor is full-text search minder geschikt om het juiste te vinden. Een oplossing hiervoor is om alleen de belangrijke woorden binnen een tekst te herkennen en van betekenis te voorzien: Named Entity Recognition. Er is een aantal benaderingen:
– dictionary-based: hierbij wordt een set van woorden gebruikt om de entities in de tekst te herkennen. Dit heeft als voordeel dat het simpel is en dat woordenlijsten beschikbaar zijn. Het nadeel is dat woordenlijsten groot zijn, maar niet compleet en de entiteiten overlappen elkaar soms.
– rule-based: hierbij wordt gebruik gemaakt van regular expressions. Bijv. woorden die met een hoofdletter beginnen zijn altijd namen of woorden die eindigen op land, weg of straat zijn altijd geografisch van aard. Iets ingewikkelder is contextual matching, waarbij de context van de woorden de betekenis geeft. Bijv. “Jan werkt bij de KLM”, waarbij “werkt bij” de relatie aangeeft tussen de naam van een persoon en een bedrijf. Het voordeel is dat de handmatig opgebouwde regels precies zijn, maar het nadeel is dat het domeinspecifiek is en een dure ontwikkeling.
– machine learning: hierbij is de computer geleerd hoe het entiteiten uit een tekst moet halen. Hierbij kan men onderscheid maken tussen supervised learning, waarbij veel voorbeelden (trainingsdata) nodig zijn, semi-supervised learning, beetje trainingsdata nodig, en unsupervised learning waarbij geen training data nodig is.
Hierna werd nog uitgebreid gesproken over Elasticsearch, een zoekmachine, die net als SOLR gebaseerd is op Lucene.
De conferentie werd afgesloten met een presentatie van Tony Veale: “Metaphors All the Way Down: The many practical uses of figurative language understanding”. Hij had het vooral over metaforen. Bijvoorbeeld over een bibliotheek waarin alle boeken die ooit geschreven zouden kunnen worden. Dus ook een boek wat een normaal boek lijkt, maar waarvan de laatste paar bladzijdes onzin bevatten, waardoor je eigenlijk niks aan het boek hebt. Zo’n bibliotheek, ook al zou die alle mogelijke boeken bevatten, zou niet zinvol zijn omdat je alleen met zekerheid kan zeggen of je het juiste boek hebt, als je het boek ook helemaal leest. Vandaar deze quote: “What makes a good library is not what you put into it, but what you don’t put into it.”
Verder had hij en zijn team onderzoek gedaan naar tweetbots die op basis van de inhoud van Digital Libraries, tweets schrijven op twitter. Daar kwamen soms hele verrassende uitspraken van de tweetbots uit, zoals:
“One does not simply walk hand-in-hand with violence.”
“Suspicions were once nurtured by informed investigators.”
Meer hiervan is te vinden op twitter onder @MetaphorMagnet, @MetaphorMirror, @bestofbotworlds en de tweetbot die delen van ebooks tweet @horse_ebooks
De volgende TPDL conferentie is op Thessaloniki in Griekenland van 17 tot 21 september 2017, dus ik hou me zeker aanbevolen.
Video in het onderwijs heeft de afgelopen jaren een enorme vlucht genomen. In mijn eigen schooltijd diende de tv vooral als tijdvulling. Hij werd naar binnen gereden als er een docent ziek was geworden of op de laatste middag voor de vakantie. Zo herinner me de film The Wave bij Maatschappijleer, die we wel 2 of 3 keer hebben gezien.
In actuele onderwijsconcepten als MOOCs en Flipped Classroom is video een belangrijk medium. Het wordt gebruikt om colleges op te nemen (Weblectures), om stof uit te leggen (Kennisclips), vaardigheden te oefenen en observaties te doen. Ook moeten studenten steeds vaker een video als opdracht maken, in plaats van een schriftelijk verslag.
Van 8-10 maart bezocht ik in Brussel de Media & Learning Conference, om me eens goed te verdiepen in het gebruik van video in het hoger onderwijs. Nu de UBL immers het beheer over de universitaire videoserver heeft gekregen (Kaltura wordt momenteel geïmplementeerd), is het zaak dat we goed weten hoe medium wordt ingezet zodat we kunnen inspelen op wat er op ons af komt.

Bij video komt veel kijken. Weblectures zijn wel de meest elementaire vorm. Maar door het opnemen van colleges verandert een normaal efemere gebeurtenis ineens in een learning object, zoals Clive Young van University College London (bekijk op Slideshare) dat zo mooi zei. En dan komen er hele andere eisen om de hoek kijken. Kun je korte stukjes uit zo’n Weblecture bijvoorbeeld ook los gebruiken, of is een andere vorm dan geschikter? Voor iedere inzet van video die verder gaat dan eenvoudige college-opnamen moet worden nagedacht over wat je er precies mee wilt bereiken, en wat dan de meest geschikte vorm is. Een goede voorbereiding en een script – hoe beknopt ook – zijn daarbij onontbeerlijk.
Video is feitelijk een nogal passief medium, de student heeft de neiging om achterover te leunen. Maar zoals meerdere sprekers benadrukten: Learning does not happen until you stretch your brain. De student dient dus geactiveerd te worden. Toverwoorden daarbij zijn Engagement (betrokkenheid) en immersion (onderdompeling), volgens spreker Jeff Rubenstein, VP of Product van Kaltura (bekijk weblecture). Dit kan bijvoorbeeld door er vragen bij te stellen. Kaltura bevat functionaliteit om een video op bepaalde momenten te larderen met quizvragen – al verschillen de meningen over de inzet daarvan (het hindert bij het kijken of scannen door een video, en het zijn vaak oppervlakkige vragen). Ook kun je studenten actief met een video aan de slag laten gaan door hen uit meerdere scenario’s te laten kiezen (zoals bij deze film over wetenschappelijke integriteit), of hen te laten reflecteren op de inhoud. Met video kun je leermomenten in een verhalende vorm verpakken, waardoor studenten zich goed kunnen inleven en de stof beter beklijft.
![]() Kaltura doet jaarlijks onderzoek naar het gebruik van video in onderwijs. In The State of Video in Education 2015 (bekijk pdf) is onder andere gekeken naar digital literacy, inzet van video in cijfers, use cases, de behoeften van docenten, en een toekomst beeld van de inzet van video in het onderwijs. Docenten blijken vooral behoefte te hebben aan eenvoudige tools en workflows, een centrale videodienst die aan de leeromgeving is gekoppeld, maar zeker ook aan training, ondersteuning en tijd om hieraan te besteden.
Kaltura doet jaarlijks onderzoek naar het gebruik van video in onderwijs. In The State of Video in Education 2015 (bekijk pdf) is onder andere gekeken naar digital literacy, inzet van video in cijfers, use cases, de behoeften van docenten, en een toekomst beeld van de inzet van video in het onderwijs. Docenten blijken vooral behoefte te hebben aan eenvoudige tools en workflows, een centrale videodienst die aan de leeromgeving is gekoppeld, maar zeker ook aan training, ondersteuning en tijd om hieraan te besteden.
De didactische en praktische docentondersteuning blijft in Leiden bij de faculteiten, waar ook de Weblectures worden ondersteund en de afgelopen jaren studio-opstellingen zijn gerealiseerd dan wel gerevitaliseerd. Ook het Online Learning Lab van Centre for Innovation in Den Haag, waar de Leidse MOOCs worden geproduceerd, heeft studiofaciliteiten. De UBL zal bij dit alles een coördinerende rol bij spelen. De Media & Learning Conference heeft veel inspiratie gebracht hoe de ondersteuning van video bij andere universiteiten in binnen- en buitenland is georganiseerd.
Zo heeft de Vrije Universiteit Amsterdam (bekijk ppt) een walk-in studio ingericht, met vaste apparatuur en beperkte opties. Dit is geïnspireerd op Valencia en is een soort tussenvorm tussen Do It Yourself en een professionele studio. Er wordt gewerkt met een standaardprocedure. Je kunt boeken via een online formulier en de URL staat klaar als je de studio verlaat. Docenten zijn erg tevreden over deze dienst.
 De Universiteit Erlangen-Nürnberg (ppt) heeft een rugzak met opnameset. Dit aanbod is met name gericht op studenten. Er is een kleine training beschikbaar, maar deze is niet verplicht. Wel geven ze er een checklist bij met camera-instellingen en andere dingen waar je op moet letten (bv. omgevingsgeluid, camera niet richting raam plaatsen). Voor de voorbereiding hebben ze schema’s om structuur te bieden bij het bepalen van de didactische opzet en het maken van een script. De Oulu University of Applied Sciences (Finland) scoort hoge kijkcijfers met een video waarin het gebruik van de camera wordt gedemonstreerd.
De Universiteit Erlangen-Nürnberg (ppt) heeft een rugzak met opnameset. Dit aanbod is met name gericht op studenten. Er is een kleine training beschikbaar, maar deze is niet verplicht. Wel geven ze er een checklist bij met camera-instellingen en andere dingen waar je op moet letten (bv. omgevingsgeluid, camera niet richting raam plaatsen). Voor de voorbereiding hebben ze schema’s om structuur te bieden bij het bepalen van de didactische opzet en het maken van een script. De Oulu University of Applied Sciences (Finland) scoort hoge kijkcijfers met een video waarin het gebruik van de camera wordt gedemonstreerd.
Inholland (spreker Zac Woolfitt, bekijk ppt) heeft workshops van 2 uur opgezet, compleet met praktijkdeel (zelf optreden in video). De deelnemers leren zo meteen wat de valkuilen zijn. Er is veel tijd voor reflectie (nadenken hoe je dit goed kan doen en hoe je het goed kunt inzetten). In het natraject zijn er coaching sessies.
Bij diverse instellingen worden studenten actief betrokken bij het produceren van video. Zij zijn vaak creatiever en handiger met video dan docenten. Een video met het studentperspectief erin is bovendien aansprekend voor de doelgroep.
De productie van video wordt zo laagdrempelig mogelijk gehouden. Er wordt daarom veel met eenvoudige middelen gewerkt, en er vindt vaak geen controleslag voor publicatie plaats (mits de video alleen intern beschikbaar wordt gesteld). Hoogstens wordt er een label (gemaakt door studenten/docenten) aan gehangen. Voor de laagdrempeligheid is het ook belangrijk om de voorzieningen en ondersteuning zo dichtbij mogelijk te hebben. Docenten kunnen vaak geen dagdelen vrij plannen en moeten het tussendoor kunnen doen.
Aanpassen en updaten zijn lastig bij video. Hier kun je al rekening mee houden bij het maken van een nieuwe video. Gebruik bv. geen ‘talking head’, maar alleen audio boven een screencast of ander beeld. Let er bij de audio op dat je af en toe een pauze laat vallen, zodat achterhaalde informatie er later weer uitgeknipt en vervangen kan worden. Deze tips zijn van Jörn Loviscach (Fachhochschule Bielefeld, bekijk pdf), in Duitsland bekend om zijn kennisclips op het gebied van wiskunde. Nog een tip van hem: Maak opnames zoveel mogelijk met publiek. Desnoods vraag je een paar mensen als publiek te dienen. Hierdoor heb je een natuurlijkere presentatiestijl, waardoor de kijkers straks ook hun aandacht beter kunnen vasthouden. Voor de geluidskwaliteit wordt aanbevolen een usb-microfoon in plaats van de ingebouwde te gebruiken.
Als uitsmijter nog een tip:
Het Erasmus+ LoCoMoTion project van Jörn Loviscach, waarbij ook de TU Delft is betrokken, start op 17 mei met de meta-MOOC Making MOOCs on a Budget, met daarin ook veel tips over het maken van video. Allemaal meedoen: Video et vinco!
[youtube https://www.youtube.com/watch?v=6oDov1qTE_k&w=560&h=315]
Het onderwerp Digitale duurzaamheid is de afgelopen jaren steeds meer in de belangstelling komen te staan, mede dankzij de in 2015 gepubliceerde Nationale Strategie Digitaal Erfgoed waarbinnen Digitaal Erfgoed Houdbaar een van de drie werkpakketten is. Verschillende erfgoedinstellingen, waaronder de Koninklijke Bibliotheek, hebben in hun beleidsplan laten opnemen dat ze binnen enkele jaren een repository willen dat beschikt over het Data Seal of Approval, een van de certificeringen voor een Trusted Digital Repository. Hiertoe heeft de KB ook de functie Digital Preservation Officer in het leven geroepen, waarvoor kort geleden is geworven. En het Nationaal Archief heeft voor het eerst een preservation policy gepubliceerd, waarin ook het ambitieniveau ten aanzien van de toegankelijkheid van de collecties op langere termijn wordt uitgelegd.

Met het inrichten van het UBL edepot hebben we in de UBL een goede eerste stap gezet op weg naar een duurzame opslag van onze digitale bijzondere collecties. Wanneer een collectie door een scanbedrijf wordt gedigitaliseerd, kunnen de ontvangen scans voortaan op één plaats worden opgeslagen, wat het overzicht bevordert. Aan medewerkers kunnen afzonderlijk kijk, upload en download rechten worden verleend ten bate van het beheer. Maar dit is slechts een eerste stap op weg naar de inrichting van een Trusted Digital Repository.
Om meer expertise te ontwikkelen over dit onderwerp heb ik eind 2015 bij de Archiefschool Amsterdam een vijfdaagse cursus gevolgd over de inrichting van een Digitaal Depot. Het woord ‘depot’ moet hierbij vooral als een metafoor worden gezien en niet als één fysieke plek. Het gaat er vooral om dat de opslag van digitale collecties zodanig is ingericht dat de bestanden ook weer gemakkelijk tevoorschijn gehaald kunnen worden als een gebruiker daarom vraagt, niet alleen morgen of volgende week, maar ook over X aantal jaar.
De cursus van de Archiefschool had een praktische insteek. Zo werd er uitgebreid aandacht besteed aan het opstellen van plan van aanpak voor de eigen organisatie. De overige vijf deelnemers waren afkomstig uit de archief- en of DIV- wereld, en dat bood wat mij betreft meerwaarde. Ik vond het interessant om te zien met welke problematiek men zich in de archiefwereld bezighoudt en wat het verschil in aanpak is tussen bibliotheken en archieven. Onderdeel van de cursus was een bezoek aan het Stadsarchief Rotterdam. Hier is men sinds enkele jaren verantwoordelijk voor de gehele keten van gemeentelijke informatievoorziening, van het inladen van data en metadata tot en met beschikbaarstelling. Het archief beschikt over een gecertificeerde digitale archiefbewaarplaats voor alle documenten die door de gemeentelijke overheid worden geproduceerd. Deze documenten dienen niet alleen duurzaam te worden opgeslagen, maar burgers moeten ze ook (digitaal) kunnen inzien. Ze hebben hier een filmpje over gemaakt, een beetje saai, maar het hele proces en de functie van het edepot wordt wel heel helder uitgelegd.

Theoretisch uitgangspunt bij de cursus was het Reference Model for an Open Archival Information System, of kort gezegd het OAIS-referentiemodel. Het is niet mijn bedoeling om op deze plaats OAIS uitgebreid te gaan beschrijven, daarvoor kun je beter het uitgebreide artikel lezen dat Barbara Sierman schreef over dit onderwerp. Maar kort samengevat is het een raamwerk dat de functies benoemd die je nodig hebt voor duurzaam beheer: ingest (inladen), storage (opslag), data management (beheer) en access (toegang). Om deze vier functies mogelijk te maken heb je daarnaast ook administratie en planning nodig. Het is dus een conceptueel model en het helpt je vooral om na te denken over het hele proces: wie gaat welke stap uitvoeren? En moeten die door een mens worden gedaan, of kan het ook geautomatiseerd? Op welke manier kunnen we garanderen dat de bestanden betrouwbaar en bruikbaar zijn én blijven?
Wat betekent dit alles nou voor de UBL? Op dit moment zijn we bezig met de inrichting van een nieuwe repository infrastructuur, waar (onder meer) onze digitale bijzondere collecties in beheerd en gepresenteerd zullen worden. Dat betekent dus dat we in potentie beschikken over twee opties voor de opslag en beheer van deze collecties, het UBL edepot en het repository, maar welke van de twee gaan we nu precies voor welke functies gebruiken? Aan deze vraag hebben we inmiddels al heel wat denkwerk besteed en op korte termijn wordt het eerste voorkeurscenario in overleg met ISSC getest.
Ook brengen we op dit moment precies in kaart hoe de workflow gaat verlopen voor het inladen, opslaan en beschikbaar stellen van scans. Welke onderdelen van de digitale objecten slaan we waar op, hoe vaak gaan we ze back-uppen, hoe zorgen we ervoor dat digitale objecten met copyright-restricties ook daadwerkelijk niet beschikbaar worden gesteld? En hoe kunnen we controleren dat alles volgens plan is verlopen? Het gaat daarbij niet alleen om techniek. Soms is het ook gewoon een kwestie van goede afspraken maken. Denk bijvoorbeeld aan een digitaliseringsproject. Als voorafgaand aan een project de projectmanager en/of inhoudelijk specialist hebben afgestemd in welk formaat en volgens welke structuur de scans en andere bestanden worden opgeleverd en wie verantwoordelijk is voor bijvoorbeeld de kwaliteitscontrole, dan is de kans groot dat het inladen van de scans in het nieuwe repository ook soepel verloopt. Samen met de collega’s van digitale diensten worden hiervoor op dit moment workflows ontwikkeld, tegelijk met hulpmiddelen zoals checklists waarin de afspraken kunnen worden vastgelegd.
Dit alles laat ook duidelijk zien dat het bouwen van een nieuw repository een complex proces is dat uiteenlopende aspecten bevat. Het gaat niet alleen om het technisch realiseren van een digitale omgeving, of om het overzetten van scans en metadata, het gaat ook om het herinrichten van processen en het maken van goede afspraken om deze soepel te laten verlopen. Genoeg werk aan de winkel dus.
Het resultaat is dat we straks (minstens) twee vliegen in één klap kunnen slaan: een prachtige nieuwe repository voor de digitale bijzondere collecties, met alle zoek- en gebruiksmogelijkheden die maar mogelijk zijn voor onze klanten, en tegelijk kunnen we dezelfde klanten een duurzame opslag garanderen, niet alleen nu, maar ook voor de toekomst!

Er vonden ook bijzondere ontmoetingen plaats tijdens de week…
Van 28 september tot en met 2 oktober vond in Granada de Digital Heritage Conference 2015 plaats. De conferentie werd dit jaar pas voor de tweede keer gehouden, maar toch lijkt het nu al een vaste waarde te zijn geworden in de wereld van het digitale erfgoed. Nergens komen er dan ook zoveel verschillende mensen bijeen die zich met één en hetzelfde onderwerp bezighouden. Je vindt er conservatoren, onderzoekers, beleidsmakers en ontwikkelaars uit de universitaire wereld, bibliotheken, musea, archeologische diensten en archieven uit meer dan 40 landen. Tegelijk met het congres vindt er ook een expo plaats, met stands van (non-)profit bedrijven die zich bezig houden met onderwerpen als augmented reality, serious gaming, digitale reconstucties en OCR. Wil je dus in een kleine week op de hoogte raken van de nieuwste ontwikkelingen in het veld, en in contact komen met collega’s uit de hele wereld, dan is dit de plek waar je moet zijn.
De conferentie vond dit keer plaats in het Parque de las Ciencias, net buiten het centrum van Granada en het programma richtte zich op 5 deelonderwerpen:

Het beursterrein
Dit betekent dat er veel hippe, grote projecten werden gepresenteerd die niet zozeer op de bibliotheek betrekking hebben, maar wel een goed overzicht bieden van waar onderzoekers op dit moment mee bezig zijn. Goed voorbeeld hiervan is het project Etruscan VR experience, waarvoor enkele hologrammen zijn ontwikkeld, maar er was bijvoorbeeld ook een presentatie over opblaasbare koepels waarmee bezoekers virtual reality reconstructies kunnen ervaren.
Ook was er veel te zien en te horen over de ontwikkelingen op het gebied van 3D scanning en -printing. Zo was de Leuvense hoogleraar Luc van Gool uitgenodigd voor een keynote over zijn bijdrage aan de ontwikkeling van 3D scanners. De door hem gebouwde portable light dome werd in eerste instantie vooral gebruikt voor wetenschappelijke analyse en presentatie van archeologische objecten, ivoren, munten en fossielen, maar kent inmiddels een veel bredere toepassing. Zo is de scanner met succes ingezet voor de digitalisering van de geborduurde boekbanden van de UB Amsterdam. Van Gool vertelde dat de prijs van de scanner inmiddels is gedaald tot 10.000 EUR, waardoor deze vorm van digitalisering ook voor kleinere instellingen betaalbaar is geworden, vooral als men bereid is om de scanner met meerdere instellingen te delen. Tatjana Dzambazova van het bedrijf Autodesk ging in haar keynote nog veel verder. Haar doel is het ontwikkelen van open source software waarmee instellingen zelf op basis van Fotogrammetrie 3D reconstructies kunnen maken.
Steeds vaker worden bij het digitaliseren van erfgoed technieken gebruikt uit andere disciplines, zoals de geneeskunde en scheikunde. Denk bijvoorbeeld aan de CT-scan die wordt gebruikt om de binnenkant van mummies te bekijken en vast te leggen. OCT (Optische coherentietomografie) , een onderzoeksmethode die kan worden beschouwd als optisch equivalent van de echografie, is ontwikkeld voor het onderzoeken van o.a. netvliezen en bloedvaten, maar wordt momenteel gebruikt om de vezels van papier en perkament te analyseren. Marc Walton liet in een helder gebrachte presentatie zien op welke manier digitalisering was gebruikt bij het onderzoek naar de prenten van Gauguin, die autodidact was als prentmaker. Als experimenterend ontwikkelde hij geheel een eigen, onconventionele werkwijze, die tot op heden kunsthistorici voor raadsels stelde. Hij schreef ook een mooie blog over het onderzoek en die is hier te lezen.
Een spectaculair voorbeeld van de toepassing van nieuwe technieken is het Venice Time Machine Project. Het Archivo di Stato in Venetië bevat 80 km aan archief, dat te fragiel is om te hanteren en daarom ongeschikt voor digitalisering op conventionele wijze. Daarom wordt er nu geëxperimenteerd met röntgentechnieken, waarmee een gehele plank in 1 keer wordt opgenomen. De boeken hoeven dus niet van de plank te worden gehaald. Vervolgens worden de banden, pagina’s en recto en versozijden virtueel van elkaar gescheiden, zodat de tekst weer kan worden gelezen.
Wanneer je trouwens meer wilt weten over de verschillende technieken voor 3D-Digitalisering, waaronder bovenbeschreven technieken, maar ook laserscanning en structured light scanning, kun je terecht bij het Kennisdossier van DEN over dit onderwerp.
Bij sommige presentaties bekroop me wel het idee dat het vooral onderzoek om het onderzoek betrof en dat een praktische toepassing nog ver te zoeken is. Zo was er een presentatie over het automatisch clusteren van kleuren in middeleeuwse handschriften wat tot dusver nog weinig concreet resultaat had opgeleverd (blijkbaar werkt het kunsthistorisch oog in dit opzicht toch beter). In een ander onderzoek werd onderzocht of de computer kleuren op schilderijen kon herkennen aan de hand van 3D-scans. De conclusie was dat op dit moment 65 % van de analyses klopte en dat er nog werd gewerkt aan de accuratesse. Tja..

Vanuit de uitkijktoren op het congresterrein had je een prachtig uitzicht over de Sierra Nevada
.
Maar tegelijk laten deze presentaties goed zien waar het onderzoek naar toe gaat. Op dit moment is het technisch onderzoek al een onmisbaar onderdeel van de restauratie- en conserveringspraktijk geworden, en in de toekomst zullen ook steeds meer traditionele kunsthistorische technieken, zoals stilistische en iconografische analyse door de computer worden uitgevoerd.
De keynote van de voormalige directeur van het Alhambra Maria del Mar Villafranca Jimenez maakte duidelijk dat documentatie inherent is aan verantwoord restauratiebeleid. De technieken die we hiervoor gebruiken veranderen alleen voortdurend: van tekeningen, prenten en foto’s, tot digitale media. Tijdens de verschillende restauratiecampagnes voor het beroemde leeuwenhof heeft men telkens weer teruggegrepen op de foto’s, prenten en tekeningen die er door de eeuwen heen van de binnenplaats waren gemaakt. Voor de laatste campagne, die onder haar supervisie is uitgevoerd, heeft men zowel voor als na restauratie de leeuwenfontein 3D gedigitaliseerd. De scans waren niet alleen belangrijk tijdens het hele restauratietraject, maar zijn ook gemaakt als documentatie en ter verantwoording voor latere generaties.
Hoewel de presentaties over 3D-digitalisering en -printing, archeologie en architectuur het programma domineerden, kon je ook zonder problemen je dagen vullen met lezingen over 2D, archieven en bibliotheken. Zo schoof ik op de eerste dag aan bij een workshop over het UNESCO-PERSIST-project (Platform to Enhance the Sustainability of the Information Society Transglobally), mede georganiseerd door DEN directeur Marco de Niet. Het UNESCO-PERSIST project onderzoekt wereldwijde trends en ontwikkeling op het gebied van selectie van digitaal erfgoed collecties. In augustus 2015 zijn de Draft Guidelines for the selection of digital content for long-term digital preservation gepubliceerd. Doelstelling voor de langere termijn is het opzetten van pilots waarmee best practices kunnen worden verzameld voor zowel selectie als management van digital born bronnen. De workshop diende als een laatste check: zijn er nog zaken vergeten die zeker in de definitieve Guidelines moeten worden opgenomen?

Aan het werk tijdens de PERSIST workshop
Belangrijk discussiepunt was wat er in deze tijd van informatie-overvloed de moeite waard is om te bewaren en wat niet. Uit de laatste Enumerate enquete bleek dat nog maar heel weinig instellingen actief beleid voeren op de acquisitie van digital born materialen. Wat voor de gebruikers van de toekomst van waarde is en wat als afval kan worden beschouwd en weggegooid, is niet zo eenvoudig te voorspellen. Zo blijken de vele -op het eerste gezicht identieke en daarom nutteloze- foto’s die we delen op social media inmiddels gebruikt te worden voor allerlei typen onderzoek, zoals bijvoorbeeld het ijsverlies van gletsjers en ontbossing. Er werd ook regelmatig een vergelijking gemaakt met archeologie, waar afval als een belangrijke bron voor onderzoek wordt beschouwd. Maar waar vinden de schatgravers van de toekomst hun digitale afvalberg/schatkamer?

De lunchtent
Ook waren er verschillende presentaties over het interPARES Trust project. Vertrouwen, betrouwbaarheid en authenticiteit zijn belangrijke concepten in de digitale informatiewereld, denk aan issues rondom cybercrime, e-commerce, copyright en privacy. Adam Jansen presenteerde een conceptueel model (door hem object-oriented diplomatics genoemd) voor het behoud van de authenticiteit van digitale records, onafhankelijk van het systeem waarin ze zijn opgeslagen. Dit is onder andere toegepast in het open source programma Archivematica. Corinne Rogers presenteerde haar onderzoek naar de hulpmiddelen die archivarissen gebruikten om de authenticiteit van digitale records beoordeelden, en de manier waarop dit volgens henzelf eigenlijk gedaan zou moeten worden. Haar conclusie was dat authenticiteit en betrouwbaarheid meer wordt verondersteld, dan werkelijk technisch uitgevoerd. Doel van het InterPARES project is het ontwikkelen van beleid en procedures om dit te verbeteren.
Dankzij de parallelle sessies zat er altijd wel een lezing van je gading bij. Maar anders kon je natuurlijk altijd nog naar de beurs. De leukste stand was wat mij betreft die van Cultlab3D van het Fraunhofer institute in München. Zij ontwikkelden een 3D-digitaliseringsstraat voor het betaalbaar en op hoge snelheid verwerken van erfgoed. Deze video geeft een mooie indruk van het proces.
O ja, en natuurlijk werden we de hele week verwend met heerlijk eten, goede wijnen, Spaanse zon en leuke excursies, waaronder een rondleiding by night door het Alhambra. Jammer dat we twee jaar moeten wachten op de volgende Digital Heritage Conference. Er gaan geluiden dat die in 2017 in Amsterdam zal worden gehouden….
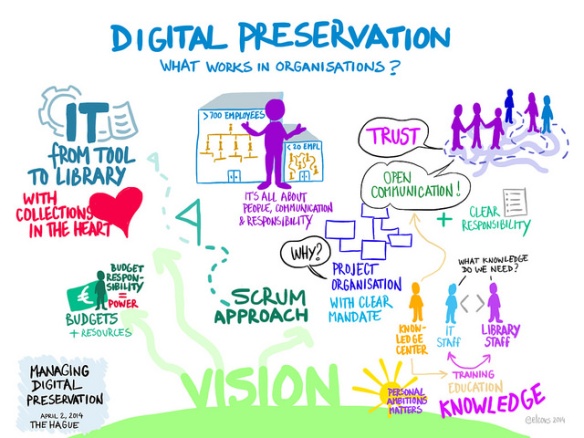
Software-ontwikkelen kan op vele manieren (watervalmethode, cowboy-coding, iteratief) maar de Agile-software-ontwikkelingsmethoden zijn de laatste jaren in populariteit gestegen. In dit blog beschrijf ik wat Agile-software-ontwikkeling nu eigenlijk is, wat de verhouding met SCRUM is en hoe we het gebruiken binnen het project “Voorbereiding nieuwe repository infrastructuur”. Het projectteam heeft ook een tweedaagse cursus gedaan om te leren wat Agile nu inhoudt en hoe het te gebruiken is.
Agile-software-ontwikkeling is een conceptueel raamwerk voor het uitvoeren van software-ontwikkelingsprojecten als alternatief voor traditionele starre praktijken.
Agile werkt met iteraties, waarbij elke iteraties eigenlijk een miniatuurproject op zichzelf is die in een korte periode uitgevoerd wordt. Dit miniatuurproject omvat planning, analyse, ontwerp, bouw, testen en documentatie. Dit miniatuurproject levert altijd iets bruikbaars op; dat kan in de vorm van een webpagina, een procedure, een prototype, een mockup, een functie of een deel van een werkend programma zijn.
Bij Agile-software-ontwikkeling ligt de nadruk op directe communicatie, bij voorkeur persoonlijk contact. Een Agile team moet op 1 locatie werken, liefst zelfs binnen een ruimte, waarbij het team in elk geval bestaat uit mensen die het product definiëren en mensen die de ontwikkeling doen. Tijdens de cursus hebben we geleerd hoe belangrijk communicatie is en hoeveel makkelijker directe communicatie gaat. Of eigenlijk hebben we zelf meegemaakt met oefeningen hoe lastig communiceren is als je niet direct contact hebt. Een van de oefeningen was om een tekening na te tekenen, waarbij de tekenaar de originele tekening niet zag. Communicatie met degene die de tekening wel voor zich had, ging door middel van briefjes. Hiermee leerden we hoe specifiek je moet zijn met communicatie, dat woorden altijd anders geïnterpreteerd worden en dat directe feedback cruciaal is.
Natuurlijk gaat het bij Agile-software-ontwikkeling niet alleen om de directe communicatie, maar heeft het meerdere aspecten. Om het hoe en waarom van deze aspecten beter te kunnen uitleggen, een korte geschiedenis van de Agile-software-ontwikkeling.
De geschiedenis van Agile-software-ontwikkeling begon midden jaren 90 als onderdeel van een reactie op “zwaargewicht”-methoden. Deze methoden zijn zwaar gereguleerd, detail-gestuurd en maken gebruik van waterval-ontwikkelmodellen. Deze modellen werden als bureaucratisch, traag en bekrompen ervaren en belemmeren de creativiteit en effectiviteit van ontwikkelaars. Hierdoor ontstaat er een aantal nieuwe methoden van software-ontwikkeling, zoals DSDM, SCRUM, Crystal Clear, Extreme Programming, ASD en FDD. Al deze nieuwe methoden hebben een aantal waarden gemeen. Deze waarden werden in 2001 in het Agile Manifesto vastgelegd en ondertekend door een groot aantal software ontwikkelaars.
Manifest voor Agile Software Ontwikkeling (vertaalde versie)
Wij laten zien dat er betere manieren zijn om software te ontwikkelen door in de praktijk aan te tonen dat dit werkt en door anderen ermee te helpen. Daarom verkiezen we:
- Mensen en hun onderlinge interactie boven processen en hulpmiddelen
- Werkende software boven allesomvattende documentatie
- Samenwerking met de klant boven contractonderhandelingen
- Inspelen op verandering boven het volgen van een plan
Hoewel wij waardering hebben voor al hetgeen aan de rechterkant staat vermeld, hechten wij méér waarde aan wat aan de linkerzijde wordt genoemd.
Het Agile Manifesto is gebaseerd op de onderstaande 12 principes:
In 2005 werd er nog een addendum geschreven aan het Agile Manifesto.
Declaration of Interdependence
“We …
- increase return on investment by — making continuous flow of value our focus.
- deliver reliable results by — engaging customers in frequent interactions and shared ownership.
- expect uncertainty and manage for it through — iterations, anticipation and adaptation.
- unleash creativity and innovation by — recognizing that individuals are the ultimate source of value, and creating an environment where they can make a difference.
- boost performance through — group accountability for results and shared responsibility for team effectiveness.
- improve effectiveness and reliability through — situationally specific strategies, processes and practices.
Dus wat is Agile nu eigenlijk:
Maar binnen de UBL maken we toch gebruik van de PRINCE2 methodiek? Betekent dit dat Agile werken en werken met PRINCE2 niet samengaan? Dat deze twee methodes elkaar bijten?
Nee, ze bijten elkaar niet, maar ze hebben wel verschillende doelstellingen. PRINCE2 is een projectmanagement methode, Agile is een software-ontwikkelingsmethode. Binnen het project “Voorbereiding nieuwe repository infrastructuur” worden beide methodes gebruikt naast elkaar. SCRUM (een Agile methode, hierover later meer) als de software-ontwikkeling en PRINCE2 als project management methode. Veel kernwaarden komen overeen bij deze twee methoden, alleen worden ze anders uitgewerkt. Het is echter goed mogelijk (en dat doen we dan ook) om binnen een PRINCE2 project de software ontwikkeling op een Agile manier uit te voeren.
We gebruiken SCRUM als Agile-software-ontwikkelingsmethodiek binnen het project “Voorbereiding nieuwe repository infrastructuur”. SCRUM werkt met een multidisciplinair team dat in korte sprints producten oplevert. Deze producten zijn meestal een aantal gerelateerde functionaliteiten binnen de repository infrastructuur. De sprint duurt bij ons 2 weken, niet langer maar ook niet korter.
De requirements die nog geïmplementeerd moeten worden, zijn beschreven in het product backlog. Deze requirements zijn geschreven in de vorm van een user story, zodat deze begrepen kunnen worden door alle teamleden en niet te technisch zijn. Aan de start van een nieuwe sprint wordt uit de items in de product back log de sprint backlog gemaakt. Dit gebeurt in een overleg tussen het team en de product owner. Er wordt een aantal items gekozen die de hoogste prioriteit hebben en binnen 2 weken te implementeren zijn.
Na elke sprint is er een potentially shippable product increment, oftewel een product dat echt aan de klant getoond kan worden.
Elke werkdag wordt er ook een scrum-meeting van 15 minuten gehouden. Hierin beantwoordt elk teamlid de volgende vragen:
Natuurlijk is er nog veel meer te vertellen over Agile-software-ontwikkeling en in het bijzonder de SCRUM methodiek. Maar voor deze blog laat ik het hier bij, maar vragen mag je natuurlijk altijd stellen (bij voorkeur via directe communicatie!).
(IGELU conference 2015 Budapest)

Nou, misschien zeggen niet álle biepers ja, en ik kan niet ontkennen dat ik met de titel van deze blog vooral gemakkelijk wil meeliften op het succes van de grote zomerhit, maar het is wél zo dat er bij de afgelopen IGELU conference nóg meer aandacht was voor Alma dan vorig jaar, zowel bij leverancier Ex Libris als bij de leden van de Ex Libris gebruikersgroep.
Dat ligt ook wel voor de hand als je kijkt naar de snelheid waarmee Alma wordt uitgerold. Op dit moment zijn er 230 bibliotheken die met Alma werken. Eind dit jaar zullen dat er 383 zijn (al moet daarbij opgemerkt worden dat ruim honderd van die nieuwe bibliotheken behoren tot een groot Noors consortium, maar toch). Ondertussen gaat de ontwikkeling van Alma gestaag door. Nog steeds wordt er iedere maand een update uitgebracht. Geleidelijk aan zal vanaf nu tot eind 2016 de interface worden vernieuwd. Een andere metamorfose, maar dan inhoudelijk, vindt plaats met de Community Zone. Die centrale database (nu nog te vergelijken met de Global Knowledge Base van SFX) bestaat vooral uit e-journals en e-books die tot nu toe vooral door Ex Libris werden toegevoegd, maar in de toekomst zullen de mogelijkheden om zelf records toe te voegen en te muteren geleidelijk worden uitgebreid, waardoor de Community Zone een soort WorldCat light kan gaan worden. Een opmerkelijke ontwikkeling.
Ook in de planning voor 2016: Benchmark Analytics. Het wordt bijvoorbeeld mogelijk om te zien hoe de snelheid waarmee een reservering wordt gehonoreerd binnen je eigen instelling zich verhoudt tot die bij de gemiddelde (Alma)bibliotheek. Ex Libris gaat ook werk maken van de opslag en het beheer van digitaal materiaal (DAM-functionaliteit). Voor de objecten die Leiden beheert, is de functionaliteit vooralsnog te beperkt. Het meest opmerkelijke in die ontwikkeling is dat er gebruik gemaakt wordt van cloudopslag bij Amazon. Ook bij het onderdeel acquisitie kwam Amazon ter sprake. Vanaf eind dit jaar wordt het mogelijk om volledig geïntegreerd binnen Alma te bestellen bij het internetwarenhuis. Integratie was toch al een veelgebruikt begrip als het ging om acquisitie. Het selectieproces wordt steeds meer binnen Alma getrokken. Nadat YBP als eerste grote leverancier aansloot op de real-time acquisition api van Alma zullen ook Coutts, EBSCO en andere leveranciers in de nabije toekomst aanhaken.

Zinsbegoocheling en beroepsverdwazing, of zag ik dit zakje snoep écht in het schap van een avondwinkel?
Dat zijn maar een paar van de krenten uit de ontwikkelpap die Ex Libris ons voorschotelde. Maar IGELU is een gebruikersorganisatie en daarom waren er met name presentaties voor en door gebruikers. Bij de Leidse afvaardiging (Hiltje, Derk-Jan, Bas en ondergetekende) was er uiteraard veel aandacht voor de ervaringen met Alma-migraties. Het was vooral goed om te merken dat Ex Libris inmiddels blijkbaar voldoende ervaring met dit traject heeft opgedaan om het redelijk gesmeerd te laten verlopen. Gebruikerstips die steeds weer terugkomen:

Oh, oh, Budapest, mooie stad achter de duinen.
Opvallend was verder dat twee universiteiten (Manchester en Sheffield) de overgang naar Alma hebben gebruikt om af te stappen van het boetesysteem. Hun oplossing is een langlopende uitleentermijn, met als voorwaarde dat de lener het werk terug moet brengen als het door een ander is aangevraagd. Beide universiteiten ervaren de aanpassing als positief. Minder rompslomp en grotere gebruikerstevredenheid zijn de belangrijke voordelen.
|
Ander nieuws:
|
Was het dan alleen maar rozengeur en maneschijn daar in Budapest (en dan doel ik uiteraard niet op de schrijnende toestanden op het station, een paar kilometer van de conferentielocatie)? Nee, zeker niet. Werken in de Cloud en met SaaS (Software as a Service) heeft ook zo zijn nadelen. Doordat alle bibliotheken eigenlijk op één Alma zitten, zijn er minder mogelijkheden om het systeem naar eigen smaak in te richten. Zo werd er geklaagd over de de api’s. Dit zijn kleine programmaatjes, vaak gemaakt door gebruikers, waarmee geautomatiseerd allerlei acties in Alma kunnen worden uitgevoerd. Er zijn er inmiddels al meer dan honderd, maar het succes van de api’s heeft als nadeel dat ze het systeem zwaar belasten en daarom heeft Ex Libris een maximum aantal api-acties per bibliotheek ingesteld. Een aantal bibliotheken was verbolgen over deze eenzijdig genomen maatregel. Ook werd er gemopperd dat er geen vrijheid is om velden te indexeren, waardoor het bijvoorbeeld lastiger kan zijn om in Alma batchmatig gegevens te wijzigen. De (wat omslachtige) oplossing is nu om de data te exporteren, aan te passen en daarna weer te importeren.
Maar dat neemt niet weg dat over de gehele linie de bibliotheken, ook de mopperende, een positieve waardering hebben voor het implementatietraject en het werken met Alma. Een geruststellende gedachte.