Je zou denken dat plaatjes aanleveren via het internet toch heel eenvoudig is. En dat is ook zo, tenminste voor de “normale” plaatjes. Maar als het gaat om plaatjes van meer dan 100 MB groot, dan wordt het wat ingewikkelder. Zeker als die plaatjes niet in zijn geheel afgebeeld kunnen worden op het beeldscherm omdat de afmeting van de plaatjes meer dan 10.000 pixels breed zijn. Je kan je afvragen of het dan verstandig is om voor het afbeelden van deze plaatjes de plaatjes in zijn geheel op de volledig beschikbare resolutie te versturen naar een scherm dat dat toch niet aan kan. Nou inderdaad, dat is niet verstandig.
Het is dan beter om een manier te hebben om het plaatje te versturen op 800 pixels breed naar iemand die een scherm heeft van 800 pixels breed en het hele plaatje wil zien. Of alleen de rechterbovenhoek van het plaatje op 800 pixels breed voor iemand die de rechterbovenhoek van het plaatje ingezoomd wil zien. Nu is dit al lang technisch mogelijk, maar sinds september 2014 is er een officiële API voor, gemaakt door het IIIF.
API staat voor Application Programming Interface. Dit is een beschrijving van hoe een stuk software communiceert met een ander stuk software. Het IIIF is het International Image Interoperability Framework. Deze API beschrijft hoe je op een standaard manier (een deel van) een plaatje kan opvragen. En dat is niet het enige wat het beschrijft, maar daarover later meer.
Wat heb je nu aan zo’n API? Als een systeem deze API implementeert, dan kunnen andere systemen daar gebruik van maken, aangezien beschreven is hoe de API werkt en hoe die te gebruiken is. Als je plaatjes van een systeem wilt halen die de IIIF API implementeert, dan is het meteen duidelijk hoe je dat moet doen. Oftewel, het is voor iedereen duidelijk welke taal er wordt gesproken en aangezien het een taal is waar meerdere partijen het over eens zijn, kan je ook gebruikmaken van de systemen van meerdere partijen. En wat voor systemen zijn dat dan? Dat kan bijvoorbeeld gaan om een systeem wat een plaatje op een nette manier afbeeldt. Dit wordt ook wel een image viewer genoemd. Door de IIIF API is het dus mogelijk om verschillende image viewers te gebruiken, zolang die aan de IIIF API voldoen.
Er zijn 2 IIIF API’s beschikbaar: de IIIF image API en de IIIF presentation API.
Met de IIIF image API is het mogelijk om informatie over een plaatje op te vragen, zoals hoe groot het plaatje is, hoe ver ingezoomd kan worden, welke formaten beschikbaar zijn en wat er allemaal mogelijk is met dit plaatje via de IIIF image API. Ook kan natuurlijk (een deel van) het plaatje op een bepaalde grootte opgevraagd worden. Om dit te doen, kan een regio (deel van het plaatje) in absolute eenheden of percentage gevraagd worden. Daarna kan opgegeven worden hoe groot het resulterende deel van het plaatje teruggegeven moet worden. Eventueel kan ook opgegeven worden dat het plaatje in kleur, grijstinten of zwartwit geleverd wordt, en eventueel geroteerd of gespiegeld.
Hoe werkt het nu concreet? Hieronder een URL wat een deel van een plaatje opvraagt:
https://images-
dev.harvardx.harvard.edu/ids/iiif/47174896/750,840,256,256/256,/0/native.jpg
 Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden:
Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden:
- https://images-dev.harvardx.harvard.edu/ids/iiif/
Dit is een IIIF image server URL - 47174896
Dit is de image identifier - 750,840,256,256
De regio van het plaatje wat gewenst is. Dit zijn achtereenvolgens de x, y en breedte en hoogte van de regio in absolute eenheden, ten opzichte van het originele plaatje. Dit kunnen ook percentages zijn. Om het hele plaatje op te vragen kan ‘full’ gebruikt worden. - 256,
Dit is de grootte van het plaatje wat gewenst is. Hier wordt alleen de breedte gegeven, aangezien de hoogte hieruit afgeleid kan worden. Aangezien de breedte gelijk is aan de breedte die eerder in de regio gedefinieerd werd, kan dit ook worden vervangen door ‘full’, wat betekent dat de volledig beschikbare resolutie wordt gebruikt. - 0
Dit is de rotatie in graden. Hier wordt niet geroteerd. Vaak worden alleen veelvouden van 90 ondersteund (dat is bij de IIIF image server ook het geval) - native
Dit is de kwaliteit van het plaatje. Hier kan ook color (kleur), gray (grijstinten) of bitonal (zwart/wit) gebruikt worden. - jpg
Dit is het formaat van het plaatje, andere waarden zijn onder andere png,tif en pdf
Op deze manier kan ook het volgende plaatje opgevraagd worden:
 https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg
https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg
Voor de duidelijkheid, het basisplaatje is steeds dezelfde, namelijk een plaatje met JPEG2000 formaat. Hieruit kunnen de andere plaatjes gegenereerd worden. De IIIF image API beschrijft alleen welk deel van het plaatje op welke manier geleverd moet worden, maar niet hoe dat gebeurt.
Ook kan de informatie van het plaatje opgevraagd worden met:
https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/info.json
Dit levert het volgende resultaat:
{
“@context”:”https://library.stanford.edu/iiif/image-api/1.1/context.json”,
“@id”:”https://images-dev.harvardx.harvard.edu/ids/iiif/47174896″,
“width”:2087,
“height”:2550,
“scale_factors”:[1,2,4,8,16,32],
“tile_width”:256,
“tile_height”:256,
“formats”:[“jpg”],
“qualities”:[“native”],
“profile”:”https://library.stanford.edu/iiif/image-api/1.1/compliance.html#level1″
}
Hieruit wordt duidelijk wat de grootte van het plaatje is (width/height), welke schalen omndersteund worden (dus hoever ingezoomd kan worden) (scale_factors), in welke grootte de verschillende delen van het plaatje het best opgevraagd kunnen worden (tile_width/tile_height), welke formaten ondersteund worden (formats), de mogelijke kwaliteiten waarin het plaatje opgevraagd kan worden (qualities) en welke versie en niveau van de IIIF image API ondersteund wordt (profile). Zoals hier te zien is, wordt versie 1.1 van de IIIF image API gebruikt op level 1. Helaas ondersteunt dit niet alle hierboven genoemde mogelijkheden.
Met de IIIF image API kan een image viewer alle informatie en onderdelen van een plaatje opvragen om die op een nette manier af te beelden, zodat in- en uitgezoomd kan worden. Een voorbeeld van hoe dat werkt is hier te vinden.
Maar dit is nog niet alles, want waar het interessant wordt, is met de tweede API, de IIIF presentation API. Met deze API kan de structurele en presentatie informatie van een object opgevraagd worden. Een object? Het ging hier toch om plaatjes? Ja, maar een object bestaat hier uit een of meerdere plaatjes. Bijvoorbeeld een schilderij kan uit één plaatje bestaan, een foto uit 2 plaatjes (voor- en achterkant), een standbeeld uit 4 plaatjes (voor- en achterkant en beide zijkanten) en een boek uit meerdere plaatjes. De IIIF image API is bedoeld om een plaatje af te kunnen beelden, maar de IIIF presentation API is bedoeld om een object, bestaand uit allerlei plaatjes, in context te kunnen presenteren.
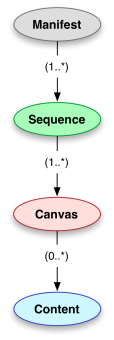 Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de OCR tekst zijn. Een beeld hoeft zelfs geen inhoud te hebben, wat het mogelijk maakt om een deels gescand boek ook netjes te beschrijven in een manifest en af te beelden (de niet-gescande bladzijdes blijven dan leeg).
Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de OCR tekst zijn. Een beeld hoeft zelfs geen inhoud te hebben, wat het mogelijk maakt om een deels gescand boek ook netjes te beschrijven in een manifest en af te beelden (de niet-gescande bladzijdes blijven dan leeg).
Wat kan je er nu eigenlijk mee? Afbeelden van allerlei materiaal, maar wellicht kan het beter getoond worden dan beschreven. Hieronder enkele voorbeelden van de UniversalViewer, een viewer die beide IIIF API’s ondersteund.
Brief: Copied letter from Francis Crick to Michael Crick
Folio: Pseudo-Albert the Great
Collectie: The biological basis of medicine
De inhoud van het “more information” tabje (rechts) wordt geleverd via de IIIF presentation API, evenals de volgorde van de bladzijdes of zelfs de hiërarchie bij het collectie voorbeeld. Bemerk dat ook de attribution, conditions of use, de license en een link naar het catalogus record in sommige gevallen zijn opgenomen. Dit alles wordt ook door de IIIF presentation API ondersteund. Bij het kaart voorbeeld wordt duidelijk hoe ver ingezoomd kan worden en hoe soepel dit gaat. Ook kan het plaatje gedraaid worden terwijl al ingezoomd is, terwijl op de juiste plek gebleven wordt. Dit alles dankzij de IIIF image API.
Het idee is om deze twee IIIF API’s te ondersteunen binnen de nieuwe repository infrastructuur. Op deze manier kunnen we de objecten mooi presenteren, gebruikmakend van een IIIF-compatible viewer zoals de UniversalViewer. Maar andere partijen kunnen ook onze objecten of delen daarvan binnen hun eigen website afbeelden. Ook kunnen we binnen de repository infrastructuur (delen van) objecten presenteren van partijen die ook de IIIF API’s ondersteunen. Dus als we van een object maar een deel hebben, kunnen we een manifest maken dat andere delen bij andere partijen die de IIIF API’s ondersteunen, ophaalt.
De IIIF API’s bieden dus veel meerwaarden, maar we moeten er nog wel wat voor doen. Helaas worden deze IIIF API’s nog niet nu al ondersteund binnen de nieuwe repository infrastructuur. Maar we kunnen dit wel zelf (met hulp van derden) implementeren. Hierna kunnen we een bestaande IIIF-compatible viewer binnen de repository infrastructuur implementeren die gebruik maakt van deze API’s.
Zoals gezegd, het wordt mooi als we plaatjes kunnen presenteren!
