 Gepubliceerd in InformatieProfessional 2017/8
Gepubliceerd in InformatieProfessional 2017/8
Op 12 maart 2015 vertelde Matthijs van Nieuwkerk in De Wereld Draait Door dat we zélf konden gaan bepalen waarmee de wetenschap zich bezig moest gaan houden. Twaalfduizend reacties kwamen er op zijn oproep om vragen in te sturen voor de Nationale Wetenschapsagenda (NWA). Of die vragen allemaal even serieus genomen zijn, valt te betwisten. Maar het beeld van samenwerking en openheid dat NWA-directeuren Alexander Rinnooy Kan en Beatrice de Graaf opriepen, was ook zichtbaar in het vervolg van het proces. De oproep resulteerde uiteindelijk in vijfentwintig onderzoeksprogramma, of ‘routes’ in het jargon van de NWA.
Door: Rob Feenstra
Een van die onderzoeksprogramma’s heet Verantwoorde Waardecreatie met Big Data (VWData). Die (meer)waarde moet de komende tien jaar tot stand komen door het verbeteren van de infrastructuur en door de ontwikkeling van nieuwe instrumenten en technieken. In de eerste periode is er met name aandacht voor multidisciplinair onderzoek en voor het opzetten van proeftuinen en projecten waarin overheid en privésector samenwerken.
Het Portfolio for Research and Innovation, dat de routes beschrijft, noemt Nederland bij uitstek geschikt om het voortouw te nemen in het onderzoek naar big data. Samenwerking tussen verschillende eigenaren en afnemers van data is in landen met datamonopolies veel minder goed mogelijk en juist aan die samenwerking wordt veel waarde gehecht. Het gaat daarbij niet alleen om universiteiten en andere kennisinstellingen, maar ook om bedrijven en maatschappelijke instellingen. Het portfolio verwijst zelfs naar het Nederlandse poldermodel, dat door zou werken in het ontsluiten van gegevensbestanden. Nederland als gidsland, we hebben het vaker gezien.
Verantwoord gebruik
VWData past ook in een internationale tendens, namelijk om beter en meer verantwoord gebruik te maken van (big) data. Een voorbeeld hiervan zijn de FAIR Principles, een set van richtlijnen om (onderzoeks)data beter vindbaar, toegankelijk, uitwisselbaar en herbruikbaar te maken (zie kader). De FAIR Principles zijn in korte tijd breed geaccepteerd en veel subsidieverstrekkers willen dat onderzoekers de FAIR-richtlijnen hanteren. In Nederland is dat, naast bijvoorbeeld de KNAW, de Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO), die het grootste deel van VWData, 2,5 miljoen euro, financiert. Bij een aantal van de nu al gedefinieerde VWData-projecten is een ruime plaats ingeruimd voor FAIR, soms gekoppeld aan zaken als privacy, digitale weerbaarheid van burgers, transparantie en waardevrijheid van algoritmen.
Zo buigt het project Fair News: Nieuwsvoorziening in een Big Data tijdperk zich over de vraag hoe ver algoritmes kunnen en mogen gaan bij het filteren van data en waar de verantwoordelijkheid ligt als er op basis van algoritmen onjuiste beslissingen worden genomen. Bij dit project, een samenwerkingsverband tussen de Universiteit van Amsterdam en de TU Delft, is ook de Volkskrant betrokken.
Een ander project waarbij het FAIR gebruik van data een grote rol speelt, is Distributed FAIR information systems to enable federated learning and reasoning. Deelnemers aan dit project buigen zich bijvoorbeeld over de vraag hoe je een FAIR datadienst opzet, waarbij concurrerende organisaties data kunnen delen en gebruiken voor een gezamenlijk vastgesteld doel zonder dat het voor andere doeleinden wordt gebruikt. Naast een viertal universiteiten nemen ook bedrijven als KLM en KPMG deel.
Eigen invulling
De vijftien FAIR Principes zijn geformuleerd in algemene termen. Zo kom je tot een brede acceptatie, maar bied je aan de andere kant veel ruimte voor eigen interpretatie. Dat kan weer tot gevolg hebben dat landen, wetenschapsgebieden, instellingen en individuen hun eigen invulling geven aan FAIR, waardoor oorspronkelijke uitgangspunten als herbruikbaarheid van data juist uit het zicht verdwijnen. De eerste projecten van VWData bevinden zich nog in de opstartfase. Het komende decennium gaan we zien hoe de deelnemers omgaan met die schijnbare tegenstelling.
Er is een lange weg afgelegd van de twaalfduizend vragen van ‘gewone’ mensen naar dit onderzoeksprogramma en het is twijfelachtig of veel van die vragen hierin beantwoord worden, maar met de gekozen insteek kunnen er in ieder geval wél antwoorden gezocht worden op vragen die maatschappelijk en economisch van belang zijn.
Rob Feenstra is projectleider/consultant bij de Universitaire Bibliotheken Leiden en heeft als aandachtsgebied bibliotheeksystemen en de digitale bibliotheek.
FAIR Principles
Een internationale groep van belanghebbenden stelde in 2016 de FAIR Principles op vanuit de groeiende behoefte om de infrastructuur voor de publicatie en het (her)gebruik van data te verbeteren. Het doel is om data Findable, Accessible, Interoperable en Re-Usable te maken. Daarbij gaat het zowel om de mogelijkheid van computers om de data te gebruiken als om het (her)gebruik door personen.
Findable (vindbaar): om goed vindbaar te zijn voor mens en machine moet er een beschrijving zijn van de metadata
F1. (Meta)data beschikken over een wereldwijd unieke en eeuwig persistente identifier
F2. Data worden beschreven door uitgebreide metadata
F3. Metadata bevatten de identifier van de data die worden beschreven
F4. Metadata worden geregistreerd of geïndexeerd in een doorzoekbare bron
Accessible (toegankelijk): de mogelijkheden en beperkingen voor toegang tot de (meta)data worden expliciet gemaakt.
A1. (Meta)data zijn opvraagbaar via de identifier door het gebruik van een gestandaardiseerd communicatieprotocol
A1.1. Het protocol is open, gratis en onbeperkt implementeerbaar
A1.2. Het protocol maakt, indien nodig, authenticatie en autorisatie mogelijk
A2. Zelfs als de data niet langer beschikbaar zijn, moeten de metadata toegankelijk blijven
Interoperable (uitwisselbaar): data kunnen gekoppeld worden aan andere data door zowel mens als computer.
I1. (Meta)data gebruiken een formele, toegankelijke en breed toepasbare taal voor kennisweergave
I2. (Meta)data gebruiken vocabularies die voldoen aan de FAIR Principles
I3. De (meta)data bevatten gespecificeerde referenties naar andere (meta)data
Reusable (herbruikbaar): de beschrijving van de (meta)data is zodanig dat er ook in de toekomst gebruik van kan worden gemaakt, zowel door mens als computer.
R1. De (meta)data worden uitgebreid beschreven met een veelheid aan nauwkeurige en relevante kenmerkende eigenschappen
R1.1 (Meta)data worden toegankelijke gemaakt door een duidelijke en toegankelijke (data)gebruikslicentie
R1.2 Het is duidelijk wat de herkomst van de (meta)data is
R1.3 (Meta)data sluiten aan op specifieke standaarden voor bepaalde onderzoeksgebieden
 Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden:
Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden: https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg
https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg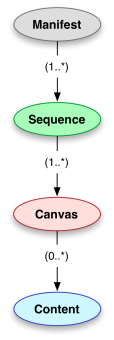 Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de
Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de 