(Vagin en peni deel 2)
 Google is als een vaste partner: je bent er aan gewend, er treedt geleidelijk aan een zekere sleur op en je kent na verloop van tijd alle gebreken van de ander, maar toch blijf je trouw, al was het maar uit gewoonte. Daarom kan ik iedereen adviseren om af en toe eens vreemd te gaan. Met een zoekmachine uiteraard.
Google is als een vaste partner: je bent er aan gewend, er treedt geleidelijk aan een zekere sleur op en je kent na verloop van tijd alle gebreken van de ander, maar toch blijf je trouw, al was het maar uit gewoonte. Daarom kan ik iedereen adviseren om af en toe eens vreemd te gaan. Met een zoekmachine uiteraard.
Met Microsoft’s Bing (www.bing.com) bijvoorbeeld, dat ooit de grote tegenhanger van Google moest worden. Dat is nooit helemaal gelukt, maar volgens de gebruiksstatistieken is het wel een goede tweede. Vagin en peni (zie mijn vorige blog) vult hij keurig aan. De autocompletefunctie is over de hele linie trouwens wat beter dan die van Google. Wanneer je op een bepaald bestandstype wil zoeken, ben je bij Bing aan het goede adres: als je filetype:docx opgeeft, vindt hij zowel de nieuwe *.docx als de oudere *.doc bestanden. Hetzelfde geldt voor Powerpoint- en Excelfiles.
Als je absoluut niet wilt dat een zoekmachine je gegevens bijhoudt zijn er talloze alternatieven voorhanden. Duckduckgo ( duckduckgo.com) is bijvoorbeeld een heel aardige zoekmachine die je niet volgt. Een handige optie van Duckduckgo is dat je heel makkelijk van regio kunt veranderen. Als ik iets wil lezen over mijn neef, die schrijver is, schakel ik over naar zijn geboorteland Nieuw-Zeeland en vind hem al in de eerste zoekresultaten, terwijl ik daarvoor bij andere zoekopties flink moet doorscrollen. Maar het handigste van Duckduckgo zijn de bangs. Via deze optie kun je je zoekactie beperken tot één bepaalde krant, database, catalogus, site enz. Er zijn duizenden van die bangs en het aantal groeit.
Het Engelse Oscobo (https://oscobo.co.uk/) houdt evenmin persoons- of zoekgegevens bij. Je ziet wel advertenties, maar je krijgt niet tot in den treuren advertenties van boormachines te zien omdat je daar ooit een keer op hebt gezocht.
StartPage van IxQuick (https://www.startpage.com/) geeft je zoekopdracht door aan Google zonder dat jouw gegevens meegaan, ook je ip-adres niet. Hiermee kun je dus via een omweggetje gebruik maken van Google, zonder dat Google gebruik maakt van jou. Op die manier kun je ook anoniem de websites bezoeken die je via de zoekmachine vindt.
Ook bij het Franse Qwant (https://www.qwant.com/) staat privacy hoog in het vaandel. Het leuke van deze zoekmachine is de vormgeving. De zoekresultaten worden getoond in drie kolommen: internet, nieuws en sociaal. Een groot voordeel van Qwant is dan het helemaal geen advertenties heeft. Het geld komt binnen doordat het bedrijf de techniek verkoopt aan ondernemingen.

Het Zwitserse Hulbee (https://hulbee.com/) houdt evenmin persoonlijke gegevens vast. Er zijn wel op de persoon gerichte advertenties, maar die zijn gebaseerd op de huidige zoekactie. Hulbee heeft een mooie woordenwolk, waarmee je je zoekactie kunt verfijnen of verleggen. De machine wordt vooral geschikt bevonden voor publieke omgevingen omdat gewelddadige en pornografische content wordt geblokt.
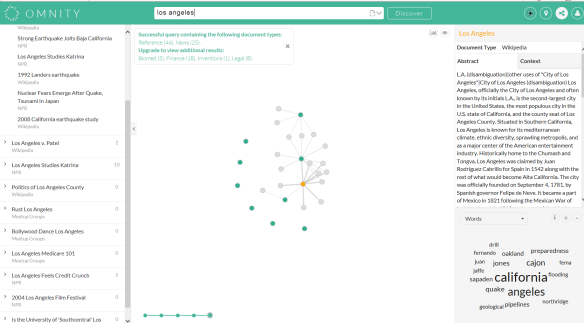
Omnity (https://www.omnity.io/) is een associatieve semantische zoekmachine met een grafische weergave. Het schijnt vooral bedoeld te zijn voor studenten en onderzoekers. Je kunt gewoon een zoekterm invullen, maar ook een volledig document als zoekobject opgeven. Ik denk dat er nog heel wat valt te perfectioneren aan deze zoekmachine, maar als je een sneak preview wilt van de toekomst van het zoeken, moet je Omnity zeker bekijken.
Wil je de wereld een beetje beter maken dan kun je gebruik maken van Goodsearch (https://www.goodsearch.com/) of Ecosia (https://www.ecosia.org/). Beide zoekmachines doneren een deel van de advertentie-inkomsten uit zoekacties aan goede doelen. Bij Goodsearch kun je zelfs je eigen goede doel benoemen. Hoe meer je zoekt, hoe meer je geeft.
Alltheinternet (https://www.alltheinternet.com/) heeft een uitgesproken ouderwetse uitstraling, maar het handige is dat je er kunt kiezen uit een stuk of 40 zoekmachines. Ook kun je je zoekactie laten uitvoeren door alle zoekmachines tegelijk. Het klinkt iets mooier dan het is, want de lijst bevat bijvoorbeeld ook de zoekmachine van Wallmart, maar er blijven genoeg mooie keuzes over.
Het Zwitserse etools.ch (https://www.etools.ch) benadert 16 zoekmachines tegelijk en laat bij ieder resultaat zien door welke machine het is gevonden.
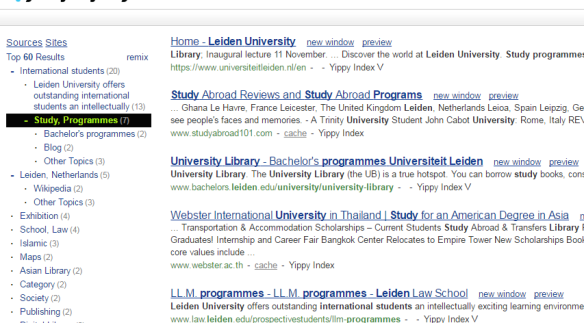
Yippy (https://www.yippy.com/) heeft een weinig serieus klinkende naam, het komt dan ook voort uit het al even koddig klinkende Clusty, maar het is wel een multisearch engine met een heel fijne feature: hij geeft bij de zoekresultaten ook een verdeling in rubrieken en toont de websites die de meeste resultaten bevatten.
SEO-slimmeriken zorgen ervoor dat ‘hun’ sites bovenaan de zoekresultaten verschijnen. Wil jij ze op jouw beurt weer te slim af zijn, gebruik dan Millionshort (https://millionshort.com). Je kunt deze search engine de opdracht geven om de bovenste zoekresultaten (van 100 tot een miljoen) laten verwijderen. Ik vraag me af of het precies werkt zoals wordt gesuggereerd, maar het levert in ieder geval verrassende resultaten op. Een mooie functie is bovendien dat je sites met advertenties kunt uitsluiten
En tenslotte een geweldig leuke semantische zoekmachine die mij persoonlijk veel voldoening heeft gebracht. Whatismymovie (https://whatismymovie.com/) geeft antwoord op vervelende vragen als ‘hoe heet die film ook alweer waarin die ene acteur (hoe heet hij toch?) de rol van evangelist speelt die in een andere film ooit de rol van Cyrano de Bergerac vertolkte?’ Type in ‘Cyrano’ en ‘preacher’ en je vindt het antwoord (Leap of faith). Zo mooi kan zoeken zijn.

 Het was een trip down memory lane, mijn bezoek aan de Internet Librarian International Conference 2016 in het Olympia Conference Center in Londen. In 1999 was ik in hetzelfde zalencomplex voor een bezoek aan de Online Conference. De enige aanpassing die het Olympia sindsdien aan de moderne tijd had gedaan was de tassencontrole, maar daar was het in Londen niet bepaald uniek in. Voor mijn werkgever moest ik destijds een verslag schrijven en ik weet nog dat ik de naam van die nieuwe zoekmachine nog even moest nazoeken in mijn aantekeningen. Oh ja, Google.
Het was een trip down memory lane, mijn bezoek aan de Internet Librarian International Conference 2016 in het Olympia Conference Center in Londen. In 1999 was ik in hetzelfde zalencomplex voor een bezoek aan de Online Conference. De enige aanpassing die het Olympia sindsdien aan de moderne tijd had gedaan was de tassencontrole, maar daar was het in Londen niet bepaald uniek in. Voor mijn werkgever moest ik destijds een verslag schrijven en ik weet nog dat ik de naam van die nieuwe zoekmachine nog even moest nazoeken in mijn aantekeningen. Oh ja, Google.



