Dit jaar wordt er vanwege de corona crisis ook door Islandora een Online event gehouden. Of eigenlijk zijn het 4 events van elk 5 uur.
Hieronder het verslag van het vierde en laatste event, gehouden op 11 augustus. Eerdere verslagen zijn hier te vinden: Islandora 8, Islandora & Metadata, en Migration.
Islandora as an IR
Eerst wordt er een overzicht gegeven van de huidige stand van zaken. Er is een aantal modules in Islandora 7 die het mogelijk maken om Islandora als een IR te gebruiken. PDF solution pack, Usage Stats, Entities solution pack, Scholar, IP Embargo zijn voorbeelden. Het LASIR project heeft ook veel gedaan voor IR in Islandora 7. Drupal 8 biedt zelf al een groot deel van de functionaliteit die deze modules verschaffen. Een ander deel zit nu al in Islandora 8. Wat vooral nog ontbreekt, zijn embargo’s en importeren van DOIs, PubMed, en dergelijke. Wat er al wel is, is LDAP for institutional login, Orcid login, OAI-PMH, Simple XML Sitemap, MetaTag (for Google Scholar), Entity Browser, Linked Data Lookup Field, PDF.js (embedded PDF viewer)* en meer.
Momenteel wordt er al hard gewerkt aan het implementeren van Embargoes. Hierbij wordt gewerkt met restricties op zowel IP als tijdsgebonden. Dit kan op “object” (node) niveau en op “bestanden” (media) niveau. Permissions by term maakt het nu al mogelijk in Drupal 8 om restricties via metadata terms te regelen. In Persistent Identifiers wordt Handles en DataCite DOIs geïmplementeerd. CrossRef DOIs wordt aan gewerkt. Er zijn plannen voor andere identifiers via een generiek framework. Over “dynamic citaties display” wordt momenteel veel nagedacht, maar er is nog geen implementatie van.
Open Access Kent State (OAKS) heeft een IR in de lucht in Islandora 8. OAKS bevat 3500 artikelen, 12 tijdschriften en 1600 conference proceedings. Discovery Garden heeft een IR oplossing gemaakt voor Islandora 8. Hier zijn speciale content types en open standaard taxonomieën voor ontwikkeld. Ook bieden ze een invoer-workflow, access control, embargo’s, rights and license management, versioning, SSO, OAI-PMH en een speciale IR presentatie laag.
Islandora as an Data Repository
UPEI (University of Prince Edward Island, de geboorteplek van Islandora) deed een project van 18 maanden om Islandora 8 als Data Repository in te richten. Dit is goed gedocumenteerd op https://islandora-rdm.researchspaces.ca/. Een onderzoeker kan hiermee de data van een onderzoek plannen, bewaren, mee (samen)werken, publiceren onafhankelijk van formaat of grootte van de dataset. De dataset krijgt een DOI, is doorzoekbaar, krijgt metadata, verwijst via ORCID en FundRef en is veilig.

Het project bevat zowel code als veel documentatie en manieren waarop een Data Repository ingericht kan worden. Een van de grote verschillen met Islandora 8 (en standaard Drupal 8) is hoe bestanden gerelateerd worden. Normaal gesproken wordt elk bestand in Drupal 8 vertegenwoordigd door een Media type. Een media type bevat velden (voor metadata), heeft versie beheer en kan bijna alles wat een Content node ook kan. Een media type heeft ook een source type. Een source type bepaalt of het om een plaatje, video, geluid of iets anders gaat. Content node is het eigenlijke item in Drupal. Dit content node kan een of meerdere media types bevatten.

Het project heeft de relatie tussen nodes, media en bestanden aangepast zodat een media type meerdere bestanden kan bevatten. Dit maakt het beheer van een dataset eenvoudiger omdat er eigenlijk een laag minder is. In de normale situatie bevat een dataset bijvoorbeeld 3 delen. Elk deel bevat een media entity voor het oorspronkelijke bestand en 2 media entities voor elke afgeleiden. Er zijn dus 9 media entities nodig.
In de nieuwe situatie hebben ze aan het media type een aantal velden toegevoegd voor deze afgeleiden, waardoor een media entity het oorspronkelijke bestand en de afgeleiden bestanden kan bevatten.
Complexe workflows
Drupal 8 bevat support voor complexe workflows om publicaties in te voeren en te wijzigen. Formulieren kunnen op diverse manieren gemaakt worden. Hier zijn veel mogelijkheden voor. Maar een ingevoerde publicatie moet nog door diverse mensen gecontroleerd kunnen worden. Die publicatie moet op dat moment nog niet zichtbaar zijn voor het publiek. De publicatie moet echter wel zichtbaar en bewerkbaar zijn voor een selecte groep mensen. Een publicatie moet eigenlijk een bepaalde status hebben waarbij een bepaalde groep mensen toegang heeft. Tussen deze statussen moet een overgang zitten van de ene status naar een andere status. Content moderation biedt deze functionaliteit. Ook kan de Rules module reageren op status overgangen. Bijvoorbeeld kan een mailtje gestuurd worden als de status wordt aangepast van een publicatie. Alle bouwblokken voor complexe workflows zijn dus in principe beschikbaar in Drupal 8. Alleen moeten deze bouwblokken nog wel “gestapeld” worden en geconfigureerd.
Dit was het laatste verslag van Islandora Online. Natuurlijk heb ik niet alle onderwerpen die voorbij kwamen behandeld, dus hierbij ook een link naar de event pagina met daarop de dagprogramma’s en een link naar de video’s die gemaakt zijn van de presentaties.
 Het congres zelf duurde 3 dagen maar werd voorafgegaan door een dag met workshops en afgesloten door een Use-a-Thon/unconference.
Het congres zelf duurde 3 dagen maar werd voorafgegaan door een dag met workshops en afgesloten door een Use-a-Thon/unconference. uitgekomen. Waar Islandora 7 nog als een hamburger werd gerepresenteerd, wordt Islandora 8 als een bento box gezien, namelijk verschillende onderdelen die goed met elkaar samengaan (samenwerken) maar uitwisselbaar zijn. Islandora 8 is veel meer verweven met Drupal 8. Waar Islandora 7 het mogelijk maakte om Islandora objecten binnen Drupal te gebruiken, is het bij Islandora 8 zo dat die objecten volledige Drupal nodes zijn. Islandora 8 maakt gebruik van nodes (waar islandora 7 een object gebruikt), files (vergelijkbaar met de datastreams in 7) en media (deze koppelt de nodes aan de files en hier wordt de technische metadata bewaard). Islandora objecten zijn dus “
uitgekomen. Waar Islandora 7 nog als een hamburger werd gerepresenteerd, wordt Islandora 8 als een bento box gezien, namelijk verschillende onderdelen die goed met elkaar samengaan (samenwerken) maar uitwisselbaar zijn. Islandora 8 is veel meer verweven met Drupal 8. Waar Islandora 7 het mogelijk maakte om Islandora objecten binnen Drupal te gebruiken, is het bij Islandora 8 zo dat die objecten volledige Drupal nodes zijn. Islandora 8 maakt gebruik van nodes (waar islandora 7 een object gebruikt), files (vergelijkbaar met de datastreams in 7) en media (deze koppelt de nodes aan de files en hier wordt de technische metadata bewaard). Islandora objecten zijn dus “

 Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden:
Waarbij de URL uit de verschillende onderdelen bestaat, die door de IIIF image API beschreven worden: https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg
https://images-dev.harvardx.harvard.edu/ids/iiif/47174896/full/100,/180/native.jpg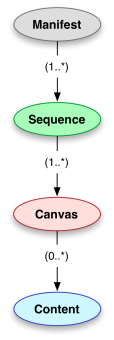 Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de
Hoe werkt het? De IIIF presentation API biedt de mogelijkheid om een manifest op te halen en in dit manifest staat beschreven hoe het object gepresenteerd moet worden en bevat een beschrijving (metadata) van het object en van de verschillende componenten van het object. Het manifest bevat 1 of meerdere opeenvolgingen (sequences) van beelden (canvas) voor het object. Een boek bijvoorbeeld heeft 1 opeenvolging van bladzijdes (in volgorde), maar er zijn boeken waar er meerdere opeenvolgingen mogelijk zijn. Elk beeld bevat ook weer inhoud (content). Dit kan bijvoorbeeld het plaatje zijn wat via de IIIF image API afgebeeld kan worden, maar het kan eveneens de