De Open Repositories (OR) Conferentie wordt elk jaar in juni gehouden, telkens in een andere stad in de wereld. Als je op de hoogte wilt blijven van wat er zoal gebeurt in de wereld van de open source repository systemen, dan is dit wel the place to be. Er zijn vertegenwoordigers aanwezig van alle grote open source systemen, zoals DuraSpace (voor DSpace), Samvera (voor Hyrax – voorheen Hydra genoemd), Islandora, ePrints, Fedora, Dataverse en Invenio. Er wordt altijd voor een uitgebreid programma gezorgd, met niet alleen lezingen, maar ook workshops, presentaties in Pecha Kucha stijl, een ideas challenge en poster presentaties.
Hierdoor trekt de conferentie een gemêleerd publiek bestaande uit ontwikkelaars, project managers en data librarians afkomstig van alle continenten. Ook wordt er altijd voor een uitgebreid sociaal programma gezorgd, waardoor je met veel collega’s in contact komt. Ook dit jaar ben ik dan ook weer met veel inspiratie en een zee aan ideeën teruggekeerd.
 De locatie dit jaar was Bozeman, Montana in de VS, een staat die bekend is door Yellowstone Park, grizzly beren en vliegvissen. Bozeman zelf is een idyllisch groen universiteitsstadje met prachtige houten huizen, dat wordt omringd door sappige groene velden en wit-besneeuwde bergtoppen. Iedereen lijkt er bovendien een pickup, een pet en een hond te hebben. Terwijl op de deur van de UB duidelijk stond aangegeven dat dieren niet welkom waren, trof ik ze regelmatig aan op de campus:
De locatie dit jaar was Bozeman, Montana in de VS, een staat die bekend is door Yellowstone Park, grizzly beren en vliegvissen. Bozeman zelf is een idyllisch groen universiteitsstadje met prachtige houten huizen, dat wordt omringd door sappige groene velden en wit-besneeuwde bergtoppen. Iedereen lijkt er bovendien een pickup, een pet en een hond te hebben. Terwijl op de deur van de UB duidelijk stond aangegeven dat dieren niet welkom waren, trof ik ze regelmatig aan op de campus:
En hoewel de meeste Amerikaanse steden per voorkeur met de auto dienen te worden doorkruist, leent deze stad zich juist voor wandelen en fietsen. Op de campus van Montana State University trof ik zelfs deze fietsreparatie-paal aan.
De studenten bleken er zelf om te hebben gevraagd en de plaatsing zelfs mede-gefinancierd te hebben. Wat een geweldige service, je vraagt je af waarom wij dit niet al lang hebben!
Montana is niet naast de deur en mogelijk maakte dit dat er maar weinig Nederlanders of Nederlands-sprekenden aanwezig waren. Naast mij waren alleen twee UBA collega’s en twee medewerkers van Atmire aanwezig, service provider van DSpace en de hoofdsponsor van de conferentie. Thema was “Sustaining Open”. Zoals ze zelf verklaren op hun website: “Submissions this year should focus on the how, why, and what it will take to make open sustainable.”

De ‘binnenstad’ van Bozeman
De eerste dag van OR staat traditioneel in het teken van de workshops. Ik had me ingeschreven voor een sessie rondom Polaris OS, een nieuw systeem waar ik nog niet eerder van had gehoord. De Franse makers presenteren het als een Next Generation Open Repository, aansluitend bij de aanbevelingen van COAR (waar ik vorig jaar ook al wat over geschreven heb). Het is volgens hen data-georiënteerd, eenvoudig te installeren en interoperabel. Het valt al snel op dat er veel tijd en aandacht is besteed aan het meertalig maken van een repository (heel praktisch voor Franstaligen natuurlijk). Ook technisch ziet het er veelbelovend uit: er is een deposit module met embargo mogelijkheden en uitgebreid rechtenbeheer. Wel blijkt uit de uitgebreide demonstratie dat het systeem toch ingewikkelder in elkaar zit dan ik dacht. Het doet me denken aan Drupal, het CMS van Islandora waar zoveel opties in ‘verstopt’ zitten dat je door de bomen het bos niet meer ziet. Het is de vraag of je dit zomaar zonder uitgebreidere training kunt gaan gebruiken in je instelling. Bovendien staat Polaris nog in de kinderschoenen. Zo is het onduidelijk of er al wel echte gebruikers zijn en ooit de start-up fase voorbij zal komen. Is er bovendien nog wel ruimte voor nog een nieuw repository (zie ook de lijst bovenaan)? In elk geval betreft het een open source systeem om de komende jaren in de gaten te houden.
De opening keynote werd dit jaar verzorgd door Casey Fiesler. Haar presentatie met als titel “Growing Their Own: Building an Archive and a Community for Fanfiction” focuste op de rol van de gemeenschap in digitale duurzaamheid. De website Archiveofourown.org (AO3) is opgezet ter vervanging van Live Journal en FanLib, twee grote platformen voor fanfiction schrijvers. Om verschillende redenen voelden gebruikers zich hier niet meer welkom. Ze hadden behoefte aan een “Space of their own, met als resultaat AO3; met 1,5 miljoen gebruikers en 0,5 miljoen werken een substantiële community. AO3 heeft vooral een archief-functie, dus alle social media activiteiten vinden plaats buiten het archief, zoals in Tumblr. Bijzonder is dat de site bijna geheel bedacht, gebouwd en beheerd wordt door vrouwen. Fiesler onderzocht deze community en stelde vast dat AO3 voor een groot deel user-driven is:

Iconen in AO3
- Er is geen betaalde directeur, board of andere vorm van commerciële organisatie: alles wordt gedaan door en voor vrijwilligers. Samen beschermen ze de fanworks tegen commerciële exploitatie.
- Een groep van vrijwilligers zorgt voor standaardisering van tags, zodat deze kunnen worden opgenomen in een folksonomy.
- Gebruikers helpen elkaar ook om technische skills te ontwikkelen waarmee ze de site kunnen onderhouden “so they can contribute to the thing they love”
- Ze hebben onder meer zelf bedacht dat er een content policy moest komen, met als gevolg een simpel systeem van icoontjes die onder meer aangeven of je een tekst mag gebruiken, aanpassen, vertalen, remixen; en waarmee tevens eventuele waarschuwingen worden aangegeven (taalgebruik, sex, geweld).
- Er wordt daarbij rekening gehouden met specifieke wensen: gebruikers wilden onder meer bijdragen die ze in het verleden hadden gepost weg kunnen halen. Omdat dit vanuit preservation oogpunt onwenselijk is, hebben ze bedacht dat je het kunt ‘verwezen’: de tekst wordt wel bewaard, maar niet meer in relatie tot jouw persoon.
- Onderzoek naar fandom wordt gestimuleerd door middel van een peer reviewed wetenschappelijk tijdschrift.
Belangrijkste advies van Fiesler: ook andere communities, zoals die van de open source repository systemen zouden zich op deze manier kunnen organiseren, om zo hun voortbestaan te garanderen.
De rol van de gemeenschap in het toekomstbestendig maken van een repository zou gedurende de week verschillende keren voorbij komen, er was onder meer een volledige sessie aan gewijd. Dit speelt vooral bij nationale, regionale en thematische repositories, waar meerdere instellingen aan bijdragen. Allen stelden vast dat het lastig is om financiering te krijgen voor het onderhoud, dit is nu eenmaal geen sexy onderwerp. De presentaties lieten zien dat er op verschillende manieren werd gezocht naar een duurzaam business model. Sommige repositories zoals het Digital Repository of Ireland zijn overgegaan op het bieden van extra diensten voor betalende leden. Anderen zoeken het vooral in de inrichting van de organisatie: door activiteiten te decentraliseren (“many people doing little jobs”), zoveel mogelijk taken te automatiseren, vrijwilligers te motiveren etc. En misschien het allerbelangrijkste: onder het mom ‘niemand is onmisbaar’ ervoor te zorgen dat er niet één persoon eindverantwoordelijk is, maar te vertrouwen op het zelforganiserende vermogen van de gemeenschap.
Opvallend was dat maar weinigen een commerciële partner in de arm hadden genomen, “van de community, voor de community”, was steeds het uitgangspunt en advertenties hebben een negatief effect op de gebruikerservaring, met name op de betrouwbaarheid van een repository.
Bij Cornell university bleek in de loop der jaren een lappendeken aan repositories te zijn ontstaan. Een werkgroep heeft voor repository managers, administratie en marketing het Cornell University Library Repository Principles and Strategies Handbook opgesteld. Het beschrijft vooral wat er allemaal komt kijken bij het beheer van een repository, en wordt gebruikt wanneer onderzoekers zich melden met de vraag om een nieuw repository. Door hierover een beter bewustzijn te kweken hoopt men dat onderzoekers eerst kijken naar mogelijkheden om gebruik te maken van bestaande infrastructuren, en niet weer een nieuwe gaan bouwen. Het handboek is voor een veel grotere groep interessant. Het geeft bijvoorbeeld ook instructies voor een file directory in een dataset, filenaam conventies, software beschrijvingen en copyrights.
De Islandora Foundation heeft verschillende kanalen opgezet om de toekomst van het repository te garanderen. Dit alles onder vanuit de idee “The sustainability of software is rooted in the sustainability of a community. Zo hebben ze een betaald lidmaatschap opgezet (wij zijn als UBL sinds dit jaar collaborator) die deelname mogelijk maakt in de Coordinating Committee en Technical Advisory Group, er zijn zelf-regulerende interest groups rondom specifieke onderwerpen en Google discussiegroep voor vragen en kennisuitwisseling. Ook wordt er enkele keren per jaar een Islandora Camp georganiseerd: het eerstvolgende is van 20-22 juni in Limerick en een delegatie van UBL zal hier heen gaan om kennis uit te wisselen.
 Tijdens de Repositories Rodeo presenteren vertegenwoordigers van alle groter open resource systemen kort de laatste ontwikkelingen, waarna er gelegenheid is tot vragen. Dit zorgde ook dit jaar weer voor een levendige discussie. Je kon hierbij goed merken dat veel platforms van project of start-up fase naar volwassenheid zijn gegroeid. Ze zijn beter georganiseerd als organisatie, en werken op verschillende manieren samen, onder meer in de overgang naar Linked Data en RDF. Ook hebben ze samen meegeschreven aan de Guidelines voor Next Generation Repositiories die in november 2017 zijn verschenen. De vraag naar waar we over 5 jaar staan leverde een aardige samenvatting op van de conferentie:
Tijdens de Repositories Rodeo presenteren vertegenwoordigers van alle groter open resource systemen kort de laatste ontwikkelingen, waarna er gelegenheid is tot vragen. Dit zorgde ook dit jaar weer voor een levendige discussie. Je kon hierbij goed merken dat veel platforms van project of start-up fase naar volwassenheid zijn gegroeid. Ze zijn beter georganiseerd als organisatie, en werken op verschillende manieren samen, onder meer in de overgang naar Linked Data en RDF. Ook hebben ze samen meegeschreven aan de Guidelines voor Next Generation Repositiories die in november 2017 zijn verschenen. De vraag naar waar we over 5 jaar staan leverde een aardige samenvatting op van de conferentie:
- “Moving forward together”: de noodzaak van samenwerking om de toekomst te garanderen. Samvera en Islandora maken al beide gebruik van het opslagsysteem Fedora. Maar zouden de beheerders niet op veel meer vlakken samen kunnen werken?
- Over 5 jaar heeft iedereen die hier behoefte aan heeft een repository: wat voor consequenties heeft dit voor groeimogelijkheden en ontwikkeling, zowel in de breedte als de diepte?
- Hoe bedien je de vele gebruikers met variëteit aan wensen? Ga je voor specialisatie, of groei in de breedte. De aanwezige vertegenwoordigers waren van mening dat ze alleen door zichzelf te concentreren op kerntaken het systeem beheersbaar konden houden.
Ook vanuit ons perspectief is dit laatste punt een actueel thema, want het heeft directe consequenties voor de inrichting van je infrastructuur. Kies je er met het oog op beheersbaarheid voor het aantal systemen zoveel mogelijk te beperken? Of kies je juist voor flexibiliteit, en zijn het de koppelingen die voor beheersbaarheid zorgen? Met andere woorden: gaan we proberen om alle wensen van onze eigen gebruikers in Alma& Islandora te verwezenlijken, of gaan we gebruik maken van verschillende, verbonden systemen?
Hoewel ik geen technische achtergrond heb, bezocht ik toch enkele sessies in de zogenaamde Developers Track. Het is interessant om te zien welke tools er zoal worden ontwikkeld, sommigen kunnen namelijk met kleine aanpassingen namelijk door ons worden hergebruikt. Terence Brady van Georgetown University Library presenteerde allereerst DSpace REST Reporting Tools die hij heeft ontwikkeld voor Dspace 5 of 6. Hiermee kun je o.a. de consistentie controleren en update files maken om metadata te repareren. Denk aan records met ontbrekende metadata, of 0 bitstreams. Volgens eigen zeggen werkt dit beter dan de search box in DSpace, of een open source tool als Open Refine.
Diego Pino, een van de ontwikkelaars die het actiefste bijdraagt aan de Islandora code, presenteerde een tool waarmee de ingest in Islandora kan worden vereenvoudigd. De Islandora Multi Importer (IMI), maakt gebruik van spreadsheets als input formaat gebruikt, waardoor iedereen ermee zou kunnen werken.
Links:
Hoewel publicatie repositories de overhand hebben op de OR conferentie, was er ook veel aandacht voor digitaal erfgoed. De UBs van Georgetown en Edinburgh voelden vorig jaar (net als wij) de behoefte om een start te maken met IIIF. Zij besloten om te beginnen met kleine aantrekkelijke collecties en zo ervaring op te doen. Interessante case study van Georgetown betrof een gedigitaliseerd archief uit de rechtenbibliotheek. In dit geval ontbraken de metadata op item niveau (die zitten namelijk alleen in de collectiebeschrijving). Door een inhoudsopgave in de viewer op te nemen hoefden ze niet met terugwerkende kracht metadata aan de items toe te voegen. Georgetown heeft een tutorial gemaakt voor het genereren van de manifesten.
Edinburg is nog een stap verder gegaan. Aansluitend op de digitalisering van de Scottish Session Papers hebben ze de catalogisering geautomatiseerd uitgevoerd op basis van de titelbladen. Zij hebben bovendien Alma en genereren de manifesten op basis van hun catalogiseersysteem. Hierna willen ze IIIF gebruiken voor de presentatie van de Mahabharata scroll, een laat 18de eeuwse rol van 75 meter lang, die in digitale vorm niet geschikt is voor traditionele viewers.
Dit riep in Edinburg wel de vraag op waar en hoe de manifesten beheerd moeten worden. Zijn dit ook objecten in het repository? En zo ja, wat voor identifiers krijgen ze dan? De UB van Toronto (Scarborough) kreeg eveneens met deze vraag te maken toen ze een manier zochten om annotaties te kunnen maken in Islandora. Omdat de standaard workflow van Islandora hiervoor niet voldeed hebben ze hiervoor een ‘web annotation utility module’ ontwikkeld, ook wel Annotorious genoemd. Hieraan zit een uitgebreid rechtensysteem gekoppeld, waarmee onder meer annotaties kunnen worden goedgekeurd. De annotaties worden als nieuwe objecten in het repository opgeslagen, met een eigen content model en metadata. Een dergelijke keuze betekent natuurlijk wel dat je erfgoed repository zich ontwikkelt tot data repository.
Ook interessant was de presentatie van Shanti Thompson over het Reuse project. Doel is het maken van een toolkit voor het meten van hergebruik van erfgoed data (d.w.z. al het gebruik buiten het kijken en downloaden in het repository om). Dit is ingewikkeld, omdat de metadata die bij een object horen tijdens hergebruik in bijvoorbeeld social media, vaak verdwijnen. Doordat erfgoedinstellingen niet weten hoe ze het hergebruik kunnen meten, of het personeel om dit te doen niet voorhanden is, zijn er maar weinig instellingen die dit doen. Een van de conclusies is dat vooral academische bibliotheken denken dat hun data alleen door academici worden gebruikt, in een wetenschappelijke context, maar dit blijkt een misvatting. Het indirecte gebruik is veel gevarieerder en door een groter publiek dan gedacht.
Er waren meer presentaties die het gebruik van het repository als onderwerp hadden. Zo onderzocht UNT Texas (een repository voor meerdere wetenschappelijke en erfgoedinstellingen in de regio) hoe gebruikers precies navigeren in hun repository. Dat bleek veel gevarieerder dan gedacht: wat wij als collectie beschouwen, hoeft niet altijd zo door gebruikers ervaren te worden. Zoeken en browsen wordt door elkaar gebruikt, over collecties en materiaal types heen. Interessant daarbij was dat tegelijk in het publicatie repository, naar scripties en naar erfgoed wordt gezocht. Gebruikers zijn blijkbaar in eerste instantie geïnteresseerd in een specifiek onderwerp. Wij hebben inmiddels al besloten om hiervoor twee verschillende “voorkanten” in te richten, maar misschien is toch nog iets om te heroverwegen? Zo zag ik dat verschillende andere repositories, zoals dat van Texas en Georgetown, eveneens een gezamenlijke ingang voor zowel erfgoed en publicaties heeft gebouwd. Tegelijk was de belangrijkste conclusie van het onderzoek van de Texanen : “Many people interact with our repository not through the front door (but through Google)”, dus je moet er vooral voor zorgen dat je hier vindbaar bent.
De stelling van Andrea Schuler, digital librarian van Tuffs university is dat je niet vroeg genoeg kunt beginnen met studenten te betrekken bij je repository. Zo creëer je bewustzijn voor open access, copyright, hergebruik en licenties in concrete alledaagse situaties. De meeste universiteiten nemen alleen scripties op, en zijn huiverig om de resultaten van bijvoorbeeld onderzoekscolleges als dataset op te nemen. Dit betekent niet dat alles de moeite van het bewaren waard is. Er is een workflow om de relevantie en kwaliteit van de data te garanderen. 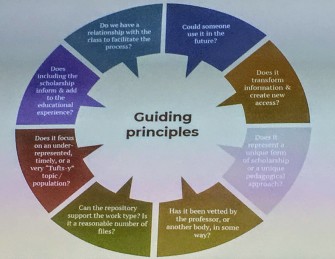 Schuler gaat zelf actief op zoek naar datasets die ze wil bewaren, zoals de resultaten van de Digital Design Studio, een ruimte voor digitale innovaties en projecten. Maar je kunt ook denken aan digitale tentoonstellingen van studenten kunstgeschiedenis. Ook blijft ze op de hoogte via de tips van vakreferenten.
Schuler gaat zelf actief op zoek naar datasets die ze wil bewaren, zoals de resultaten van de Digital Design Studio, een ruimte voor digitale innovaties en projecten. Maar je kunt ook denken aan digitale tentoonstellingen van studenten kunstgeschiedenis. Ook blijft ze op de hoogte via de tips van vakreferenten.
In diverse sessies kwam het gebruik van Linked Open Data binnen het repository aan de orde. Nieuwe generatie systemen zoals Samvera ondersteunen dit standaard. Islandora biedt dit aan in de vorm van Claw, de opvolger van de huidige installatie. Een mooi voorbeeld hiervan is de site die is ingericht voor het onderzoek naar zogenaamde Dragomans (1550-1750), vertalers, tolken en gidsen die in dienst waren van het Ottomaanse Rijk. De projectsite ziet er prachtig uit, je kunt vrijuit linken tussen personen, documenten, vertalingen en transcripties. Wel blijken de sites die zijn gebaseerd op Claw ook nog grotendeels “boutique sites” te zijn. Ik voorzie nog niet dat wij op korte termijn al onze data naar Claw moeten gaan overzetten (gelukkig, want we hebben de huidige migratie nog niet eens af….).
Mijn sessie had als onderwerp digital preservation (ik zat dit keer eens niet in een erfgoed-blokje). Hierdoor was de samenstelling gemengd, wat zowel voor- als nadelen heeft. Ook dit keer heeft iemand keurig notities gemaakt en in Drive opgenomen. De eerste presentatie was vooral technisch van aard en beschreef een tool voor het stroomlijnen van OAIS protocollen. Evviva Weinraub leidt momenteel een onderzoek naar de integratie tussen lokale repositories en gedistribueerde diensten (denk aan de content in ons eigen repository versus Delpher). Vragen die aan bod kwamen waren: hoe worden objecten geselecteerd voor opname in een van beide systemen, wat wordt waar op genomen (of gedupliceerd), hoe gaat men om met versiebeheer en interoperabiliteit? In de meeste gevallen worden meerdere kopieën bewaard, maar los van elkaar. Hiervoor blijken bovendien allerlei systemen te worden gebruikt.

In Amerikaanse UBs worden nog opvallend veel Homegrown systems gebruikt.
Een volledig rapport vind je hier:
https://arch.library.northwestern.edu/downloads/zk51vg841?locale=en
Mijn eigen presentatie ging over het duurzame beheer van een groeiend repository: hoe zorg je ervoor dat overstap naar grootschaliger en professioneel beheer soepel kan worden verlopen welke rol kan certificering hierbinnen spelen? Voor degenen die aanwezig waren bij de eindpresentatie van de stage van Federica Pugnali geen nieuw onderwerp, want tijdens deze gelegenheid hebben we hier ook al uitgebreid over gesproken.
De afsluitende Keynote was van Asaf Bartov, die zich zelf als open access activist profileert. Hij werkt voor de Wikimedia Foundation en hoewel hij dus geen bibliothecaris is, heeft hij tijdens de hele conferentie laten zien erg betrokken te zijn bij het onderwerp. Zo heeft hij op dag 1 een workshop gegeven over Wikipedia en was hij de gehele week aanwezig om te luisteren, discussiëren en ideeën op te doen. Tijdens zijn afsluitende keynote waande ik me even in Cuba: hij praatte met gemak 2 uur vol, en was zonder veel problemen ook de rest van de middag doorgegaan, maar dit liet ook wel wat zien over zijn betrokkenheid. Voor wie geïnteresseerd is, zijn gehele presentatie is hier te bekijken, of lees een samenvatting op papier. Zijn belangrijkste boodschap:
- De open movement is mainstream geworden
- De open movement en erfgoedinstellingen zijn natuurlijke partners. Zo doneren wij samen veel data aan Wikimedia, die ons vervolgens helpt om deze te verrijken en standaardiseren, bijvoorbeeld via Wikidata.
In veel instellingen zijn er al Wikipedians in residence en er wordt veel gebruik gemaakt van de kracht van crowdsourcing . Zo zijn met behulp van medisch specialisten de pathologie afbeeldingen van Calicut Medical college in India van metadata voorzien. Zoiets zouden wij natuurlijk ook kunnen doen met onze anatomische tekeningen.

Hebben bibliothecarissen meer problemen dan oplossingen? De Ideas Challenge leverde 100 user stories met problemen op, en maar 6 groepjes met een oplossing.
Elk jaar wordt er op OR ook een Ideas Challenge gehouden. Ik had nog niet eerder meegedaan, maar het leek me dit keer een mooie gelegenheid om met collega’s in contact te komen. Iedereen mag een probleem voorleggen in de vorm van een user story. In mijn geval heb ik beschreven dat de onderwerpstrefwoorden in ons repository vaak de lading niet dekken: onder meer doordat KIT KITLV en UBL een hele andere beschrijvingstraditie hebben, zijn vooral de foto’s van heel verschillende metadata voorzien. Dit zorgt voor een vertekend beeld bij gebruikers. Door op bv paard te zoeken denk je alle foto’s met een paard er op afgebeeld in je trefferslijst te krijgen, maar dat kan ook zomaar slechts een derde zijn, omdat KIT en KITLV dit trefwoord nooit hebben toegekend. Vervolgens mocht je met een zelf gekozen groepje een van de problemen kiezen en samen uitwerken tot een mogelijke oplossing. Aansluitend op de laatste keynote presenteerde elke groep de resultaten, en er waren natuurlijk coole (very nerdy) prijzen.

Mijn groep was heel divers, met een Amerikaan, een Amerikaanse Indiër, een Australiër en ikzelf, een mix van ontwikkelaars en (data-) managers. Wij hadden als taak om GDPR – zoals de rest van de wereld de nieuwe privacy wetgeving noemt – aan de man te brengen, zodat data-managers begrijpen wat er van hen wordt verwacht wanneer ze een dataset opnemen.
Hoewel we met onze presentatie niet wonnen (volgende keer meer inzet op de fun-factor!) had ik heel veel plezier gehad en drie nieuwe vrienden gemaakt. Bovendien voelde ik me alsnog een winnaar. Want van de 100 ingezonden vragen werd die van mij gekozen door de winnende groep (zie voor de presentatie met live demo hier). Zij stellen voor om IIIF en beeldherkenning hiervoor in te zetten. Op basis van de trefwoorden die wel zijn toegekend kun je door middel van software laten zoeken naar alle overige foto’s die ook een paard tonen, ook als is dit trefwoord niet toegekend. Dit zou een leuke pilot zijn voor het ontwikkelen van innovatie in de bibliotheek.
Volgend jaar wordt het hele circus iets dichterbij georganiseerd, namelijk in Hamburg. Het zou toch mooi zijn wanneer we dan met een wat grotere groep UBL collega’s aanwezig konden zijn, want niet alleen de prachtige Fedora T-shirts maken het de reis de moeite waard.



 You can try it out yourself here:
You can try it out yourself here: 
 Tijdens het bijwonen van de panel sessie van de Confederation of Open Access Repositories
Tijdens het bijwonen van de panel sessie van de Confederation of Open Access Repositories 
 Ook interessant was de paper over
Ook interessant was de paper over 
 Ook kregen we een uitgebreide tour langs de verschillende bibliotheeklocaties, waar we ons vergaapten aan de faciliteiten. Zo waren er overal
Ook kregen we een uitgebreide tour langs de verschillende bibliotheeklocaties, waar we ons vergaapten aan de faciliteiten. Zo waren er overal